












事例190
表計算アプリで実感するデータベースの考え方の必要性
近江兄弟社高校 長谷川友彦先生

今回の発表にあたって、最初にたった一つのことを申し上げたいと思います。非常にシンプルなことで、私が目指しているのは、本当にどこの学校でも実践できるような、スタンダードな授業実践で、先進的なものを目指しているわけではないということです。ですので、ぜひ多くの学校で取り組んでいただければ、と考えております。

そのときの結論としては、データベースの内容を取り扱う際に、いわゆるデータベースの教科書通りに行うよりも、まず「実世界と情報の活用」ということを学習した上で、関係モデル、そして関係演算と進んでいくと、スムーズにいくというものでした。
今回の発表も、この続きの話になりますが、あれから8年ほど経って、今、あのデータベースの実践がどのように変わってきたか、という話をいたします。
個人情報と情報システムの関係の中でデータベースを学ぶ
「情報Ⅰ」において、データベースの分野は、「情報I」の学習指導要領の「(4)情報通信ネットワークとデータの活用」の、ア-(イ)の部分にあたります。今回の内容は、昨年度の実践をベースにした5時間の構成となっています。


1時間目に、プライバシーの権利について扱いました。これはデータベースの内容とは直接関わらないので、省いてもよいのかもしれません。
ここで取り扱う個人情報は、いわゆる氏名やメールアドレスといった狭い意味の個人情報ではなく、その人が何を購入したのかとか、webでどんなページを閲覧したのかとか、いったことまで含む広義の個人情報です。

そうすると、その人に関わるありとあらゆることが個人情報になり、それらの個人情報が社会の中で実際に活用されている、ということを話しました。そして近年、その中で新しいプライバシーの権利の考え方も提唱されています。
かつてプライバシーの権利というのは、自分のことを放っておいてもらう権利や、私生活を公開されない権利といった意味でしたが、今は自分に関する情報、つまり個人情報を、自らがコントロールできる権利と捉えられている、ということです。ですから、この章全体を通して、個人情報というものを一つ柱にしつつ、それと情報システムの関係でデータベースを取り扱う、という流れで授業を組み立てていきました。

POSシステムを例に個人情報の活用と情報システムの仕組みを考える
2時間目は、個人情報の活用と、その裏にある情報システムについて考える授業です。POSシステムを例に取って、実際に情報がどのように活用されているのかということを、生徒たちと一緒に考えていくという展開をしました。
POSシステムであれば、大体どのぐらいの年齢の、男性か女性かが、何を買っていったか、という程度の情報ですが、そこにポイントカードが導入されると、「どんな人が買っていったか」ではなく「誰が買っていったか」という、ピンポイントの情報に変わってきます。

そして、その人がどんなものを購入し、どんな行動をしたかといったことがAIで解析される中で、この人にはこういうものがお勧めできるという、いわゆるレコメンドに広がっていきます。こういったことを、コンビニの例を取り上げながら、生徒と一緒に考えていきました。
これは言うなれば、個人情報を分析することで、「君の好きなものはこれだよね」と言い当てられてしまうということになります。

まず「関係モデル」を理解する
その後、「関係モデル」を取り上げました。データベースというと、「関係データベース」が思い浮かんで、そこでは表とか、アクセスで管理するとか、SQLを使う…ということになるのですが、生徒たちには、「ふだん皆が使っているサービスやアプリの裏側にはデータベースというものが働いているんだよ」ということを意識させながら、その中で非常によく使われているモデルに「関係モデル」というものがある、という流れで説明します。
生徒には、まず「関係」の概念を理解させます。データは、それぞればらばらの状態では何も意味を持っていませんが、それらが関係することによって、「情報」になっていきます。
これは、一連の情報を表の形で格納していくことでできるんだよ、という考え方を最初に提示した上で、実際どのようにデータが格納されているのか、ということを見せます。

そして、このような表を使って「海山商事とどんな取引をしている?」ということを読み取らせる実習を行い、それを通して「関係モデル」とはどのようなものか、ということを実感していきます。

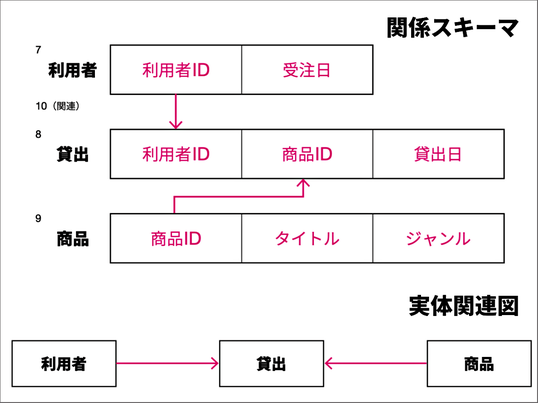
その上で、「どんな情報をどのように格納するか」という設計が非常に大事であることを伝えます。「関係スキーマ」とはどんなものかを示し、それを読み取って実体関連図を書くといった実習を、その時間中に行います。

SQLエディタを使って関係演算をやってみる
ここまでは全て紙の上で行ってきましたが、これを実際に、たくさんあるデータの中から、コンピュータで情報を取り出すという体験をしてみよう、ということで、関係演算に取り組みました。ここでは、sAccess(※2)を使いました。
※2 http://saccess.eplang.jp/try/
以前は、このスライドの左側にある、日本語でコマンドを打つことができるsAccessを使っていましたが、ある研究論文で、「生徒にはsAccessよりも真ん中のSQLエディタを使うほうが簡単でわかりやすかった」ということが書かれていました。
SQLエディタは、ブラウザ上でSQL を用いてデータベースの操作実習が行えます。
そこで、一度試しにSQLエディタを使ってみました。このようにSQLを打ち込んで送信すると、画面下のように結果が出てくるというものです。
実際に使ってみると、生徒たちにはこちらのほうがスムーズに実習できていたので、それ以降はSQLエディタを使っています。

さらにデータの一元化に取り組んでみた
ここからが今回の本題です。
例年は、このSQLをやったところで授業を終えていましたが、昨年はコロナの関係で、「情報」の授業時間数が逆に増えたので、今からお話しする部分を1時間、後に追加してみました。
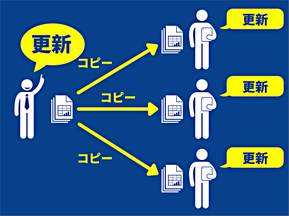
何をしたかと言いますと、まずスプレッドシートをこちらで作って生徒に配布しました。そして生徒たちに、「このセルをこのように変えてください」「ここはこういうふうに更新してください」という指示を矢継ぎ早に出します。
生徒は、聞いたことをすぐに反映させるためにそれぞれ更新作業を行いますが、どんどん指示を出していくと、やはり途中で付いて来られない生徒も出てきます。
そして、あるところでいったん止めて、「皆にやってもらったけれど、誰のスプレッドシートが一番正しいと思う?」と聞くと、「もう全然、ついていかれへんかったわ!」といった声が上がりました。

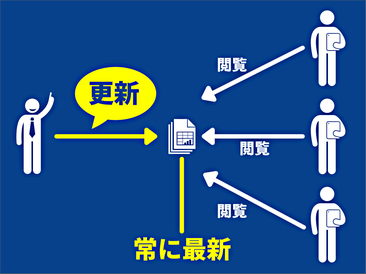
そこで、皆がそれぞればらばらやっていると良くないね、ということで、次に、スプレッドシート一つ用意しておき、それに対する閲覧権限を生徒に与えます。そして、私の方でこのスプレッドシートの更新を行っていきます。そうすると、生徒の手元では、常に更新された最新の情報が見られるので、常に完全な情報がきちんと見られます。この体験から、スプレッドシートを一元管理することの有用性が理解できました。
次に、生徒たちにこのスライドのような2つのスプレッドシートを配布して、デザイン、見やすさ、扱いやすさの点から比較させました。
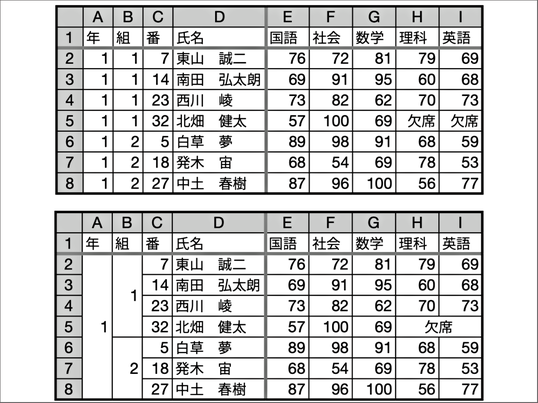
まず、デザインについては、やはり生徒たちは、下段のシートの方がすっきりして見やすくてよい、という声がほとんどでした。
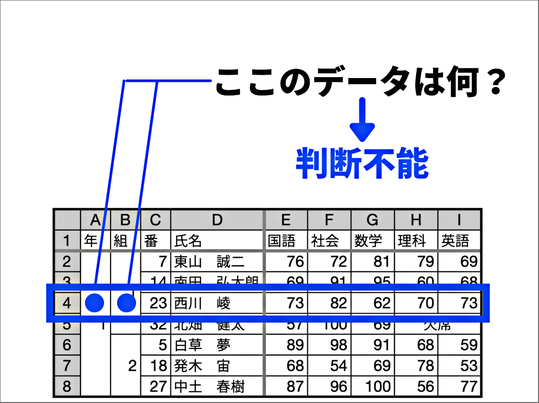
しかしこのシートでは、例えば23番の生徒の学年や組のセルに入っているデータは判断できないという不具合が出てきます。ですから、データとして取り扱うには、全てのセルにきちんとデータが入っている必要があります。
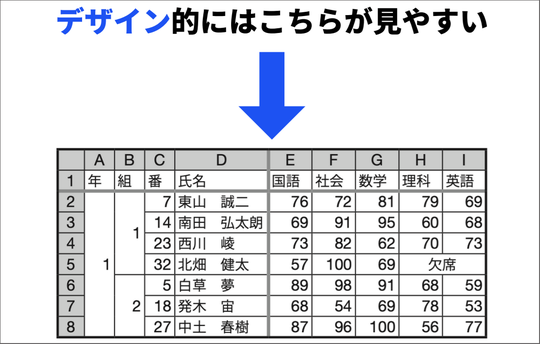

具体的には、先ほどの下段のシートにフィルターを設定させると、セル結合があるとフィルターが適応できないのでデータとして扱うことができない、ということを実感させました。
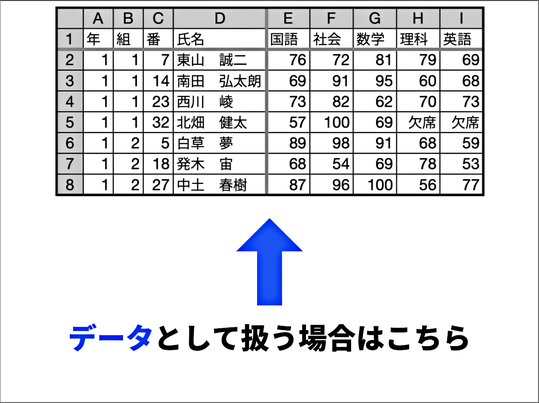
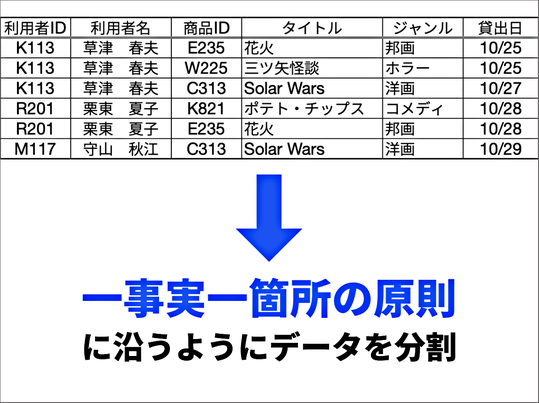
ここまでで、このようなデータを扱うときには、一つのレコード、すなわち関係が必ず一つの情報になっていることが必要になる、ということをしっかり理解させました。
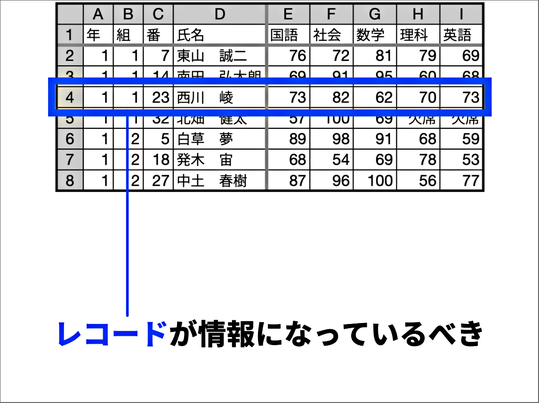
「データ」と「デザイン」は別のものであることを理解させる
ここで非常に大事な観点は、「データとデザインの分離の原則」ということです。
情報デザインにおいては、テキストをベタ打ちしたものに構造を付けたものが「データ」です。そこにCSSでデザインを乗せていく。その構造化されたデータとデザインは別のものです。人間が情報を受け取るのは、あくまでもデータの方であり、デザインはそれをわかりやすくするために使われるものです。ですから、データとデザインは一緒に扱うべきではない、ということです。
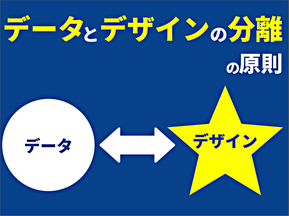

この概念は、「情報デザイン」の単元で一度、話したことではありますが、再度ここで、「データとデザインの分離が常に求められる」いうことを強調します。
その上で、データをどのように捉えていくのか、ということで、このような表を配りました。この表には、実はいろいろなところで突っ込みどころがあります。
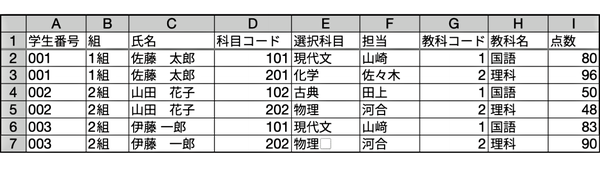
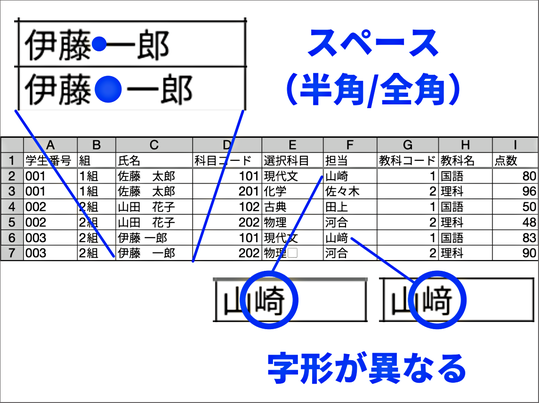
例えば、一番下の「伊藤(全角スペース)一郎」さんと、下から2番目の「伊藤(半角スペース)一郎」さんは、コンピュータからすると別人です。
ですから、フィルターを適応して、「伊藤一郎」さんを選ぼうとしても、2種類あってどうしよう、ということになります。
また、人間が入力すると、例えばヤマザキさんの「サキ」の字が異なってしまってうまく選択できないということも出てきます。
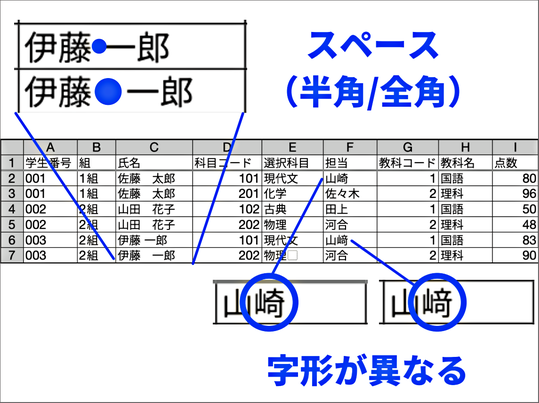
こういったことは、例えばデータ作成の担当者が変更になった場合、実際に生じる問題です。変わった担当者が一つひとつ更新していくときに、ひょっとすると先ほどのように打ち間違いが出てくるかもしれない。これでは、データに矛盾が生じることになってしまいます。
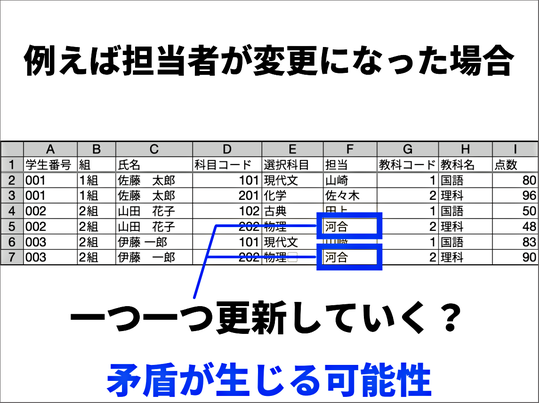
そこで、「一事実一箇所の原則」ということを説明します。これにもとづいて、データを分割し、最終的にこのような「関係スキーマ」と実態関連図を作るまでの演習を行いました。
データベースは少々影が薄い?けれど…
生徒たちに取った自己評価では、理解度は5段階の4.19ということで、まあまあそれなりかな、というところです。
ただ、やはり関係モデルやSQLといった技能を身に付けるというところでは、ちょっと低いスコアになっています。

生徒のコメントでは、「コピーしたものを送るのではなく、共有できるものでしておくと、いつも更新された状態で情報を知ることができ、効率も良く、いいなと思った」というものがありました。また、「自分で情報から知りたいことを調べたり、関係スキーマなどを使ってまとめたり、難しかったけど意味を理解してできた」、「関係モデルの設計やSQLを使うことで、データベースからさらに整理されて見やすいし、とても便利だと感じました」といった声が聞かれました。
最後に、この「4.情報通信ネットワークとデータの活用」では、ネットワーク、データベース、それから、データの分析・統計を扱いますが、データベースの部分はちょっと影が薄いかな、という気がしていますが、ぜひ皆さんにデータベース取り組んでいただきたい。そして、この授業展開を参考にしていただけると嬉しいと思います。
[質疑応答]
Q1.先生は生徒が自らデータベースを作成するような作業は、何かやらせていらっしゃるのでしょうか。
A1.長谷川先生
できていません。現在は、年間の他との兼ね合いを考えると、正直時間数的にはこの4、5時間が限界かなと思っているところです。もう少し時間数があればと思うのですが。
Q2.このデータベースと表計算は、生徒は「そんなの、ふつうのExcelでやればいいじゃない?」と思わないでしょうか。実際、私の学校の生徒にも、「データベースとExcelって何が違うの?」という子もいます。先生が、「これはデータベースを使う意味があるんだよ」ということをどのように指導されてるのか、その辺りも教えていただければと思います。
A.長谷川先生
やはりこの「一事実一箇所の原則」のところですね。データベースを使わないと、どうしても矛盾が生じてしまうという可能性があるよ、ということ。
もう一つは、「ここのデータは何?」で、フィルターができないということ。このデータの扱いやすさと見た目の見やすさとは違うんだというところですよね。このフィルターについては、実際生徒にやらせてみました。
Q3.表計算ソフトは、表のマスタを直接修正しますが、データベースは、結合にしろ、射影にしろ、選択にしろ、いろいろ作業するときには、データを引っ張ってきて新たに表を作り直すという考え方ですよね。その辺については、どのように生徒に意識させているのでしょうか。
A3.長谷川先生
最初に、ここから情報を読み解いていくという実習、これは紙ベースで行います。ここで、いろいろな情報同士を結合していけるということが実感できるかな、と思います。ここについては、生徒から「すごく面白かった」とか、「こうやって情報同士をつなげているんだ、ということが実感された」という声は出ていますね。

Q4.生徒の実習はないとのことですが、評価は実技ではなく、定期試験でこの範囲の問題に取り組ませるということでしょうか。
A4.長谷川先生
SQLのところは、実際SQLエディタで実際に問題を解かせて、その解答を点数を付ます。もちろん、もう正解が決まっているものです。あとは、定期試験を実施します。
第14回全国高等学校情報教育研究会全国大会(大阪大会) 口頭発表 より