












事例321
情報Ⅰの授業で仮説検定を扱った!
神奈川県立横浜翠嵐高校 三井栄慶先生

今回ご紹介するのは、仮説検定に関わる授業実践です。具体的には、正規分布、有意水準、t検定をかけるときのT.TEST関数、区間推定であればCONFIDENCE.T関数などを扱っています。
これらを知識としては知っている、という先生方も多いかもしれませんが、ではどれくらいの学校が実際に授業で扱われているでしょうか。今回は、本校で実施した仮説検定の授業をご紹介したいと思います。
授業実践への様々なハードル
まず、そもそもなぜ仮説検定の実践が少ないのか、というところについて考えてみると、生徒側からすると、事前の知識定着がかなり大きく成否を分けるということがあります。
「帰無仮説」「対立仮説」「有為水準」などの用語が難しく、これが理解できていないと、演習で考えようとしてもお手上げ、ということがあると思います。
一方、教員側の視点から見ると、題材を何にしたら良いかわからない、検定に耐えうる題材の選定が難しいことが挙げられます。そして、そもそも指導に自信がない、ということも大きいのではないかと思います。

そこで私は、「ラーメンの価格」を題材にしてt検定を行う実践を行いました。
先に、実際に取り組んで感じたことを3点簡単にまとめると、まず生徒達は主体的に取り組んでいました。やはり、ラーメンの価格というのは、生徒には非常に身近でわかりやすかったようで、相乗効果として、「総合的な探究の時間」で実際に仮説検定を行おうとする生徒も出てきました。
ただ正直なところ、検定の精度については課題を感じている部分もあるので、今後もいろいろ考えていかなければと思っています。

数学では「仮説検定」をどこまで学んでいる?
まず前提として、本校の数学科で仮説検定をどこまで取り扱ったか、というところについて、スライドに示したキーワードについて、数学の先生に話を聞いてみました。
私が話を聞いた所感としては、正規分布の重要性は十分に取り扱っています。また、帰無仮説、対立仮説、有意水準という言葉もしっかり扱い、検定の手順についても十分に指導していただいていました。
ただt検定については、教科書の本文中に取り扱いが全くないため、数学科ではt検定の理論的な扱いできていないということがわかりました。

授業の流れ~数学の復習に加えて、仮説検定の「意味」と「できること」を重視
それを踏まえて今回考えた授業の大体の流れがこちらです。
まず、数学科の復習も含めて、演習を交えながら2項分布と正規分布を扱いました。
t検定については、理論的な背景というよりは、t検定でできることと、T.TEST関数で実際にやってみることを重視しています。
区間推定についても、その意味と、CONFIDENCE.T関数を使うとできるという説明にとどめました。
このように、各検定の意味と使い方を軽く学んでから、5時間目と6時間目でラーメンの価格に関する仮説検定の演習を行いました。

※クリックすると拡大します。
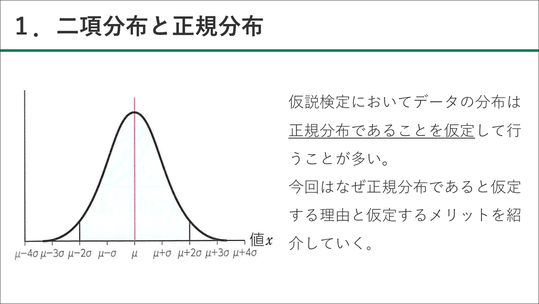
■二項分布~「なぜ正規分布が重要か」を確認する
ここからは、実際に行った授業を紹介していきます。まず二項分布の重要性について説明します。
生徒は二項分布、正規分布が重要であるということは知っていますが、情報科で扱うにあたっては、「なぜ正規分布が重要なのか」というところを考えさせました。
※クリックすると拡大します。
実際にGoogleスプレッドシートで計算をするときにも、「NORM.S.DIST(Z)という関数を使って計算するんだよ」ということをレクチャーし、演習では実際に「『情報I』の試験の得点分布が正規分布に従うものとしたときに、自分の成績は上位からどれくらいの位置にいるか」ということを確認させる演習を行いました。


■Z検定~帰無仮説・対立仮説の意味をしっかり理解し、検定の手順を確立する
続いてZ検定です。
ここでは、帰無仮説・対立仮説という言葉をしっかり理解した上で、実際の検定の手順をまず確立させることが重要になると思います。

そして、帰無仮説が棄却された場合・されなかった場合はどう考えるか、ということを押さえます。

演習問題は、数学のテキストから取ってきたものです。これをExcelで計算させます。

実際にはGoogleスプレッドシートで、Zを計算した後、NORM.S.DIST(Z)を使って確率値の値を出し、その値が大きければ棄却、という判定を行います。

※クリックすると拡大します。
■t検定~理論的な背景も扱い、実際に使う場面をイメージさせる
t検定については、少し理論的な背景も加えます。
通常は母分散がほとんどわからないというところから、t検定の必然性を高めるということを行います。

実際はt検定での分布の形は、サンプル数を大きくしないと検定の使用には耐えられないということを説明して、よく「サンプル数が30以上あれば信頼できる」というのは、こういったところから出てくるんだよ、という話もしています。

※クリックすると拡大します。
演習問題では、T.TEST関数の使い方を重点的に指導しました。
特に、対応あり・対応なしの同分散、対応なしの異分散という場合分けについては、話はしているものの、実用ベースでは、いわゆるWelchのt検定(対応なしの異分散)でやることが多い、というようなことも話しました。

この段階では、数学のテキストにあるような演習問題を使って、スプレッドシートでT.TEST検定を行いました。


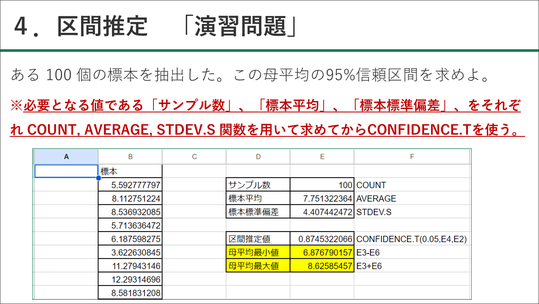
■区間推定~CONFIDENCE.T関数を使って実際に平均値を推定してみる
続いて区間推定です。
区間推定の意味合いについては、数学科でも指導されているので簡単になぞっていきますが、情報科では、主にt分布に寄っている、という前提のもと、CONFIDENCE.T関数を指導しました。

CONFIDENCE.T関数で表される値はどの部分か、ということも確認して、実際はサンプル数、標本平均、標準偏差をそれぞれ求めてからCONFIDENCE.Tを使う、という手順も指導しています。

※クリックすると拡大します。

※クリックすると拡大します。
演習問題としては、ある田んぼの稲穂の米粒の数をスプレッドシートで提供して、田んぼの米粒の数は平均どのくらいか、ということを推定しました。

■ラーメンの価格差には何が影響するか~実際のデータを使って仮説検定をしてみる
ここまでの準備を経た上で、実データを使って仮説検定を行います。
まず今までの練習と、今回の演習は何が違うのかを確認した後、親しみやすい素材として、醤油ラーメンと味噌ラーメンの値段に差があるのかということを考えます。

※クリックすると拡大します。
サンプルとして、今回は「ラーメンWalker神奈川版」からデータを拾って、教員の方でスプレッドシートに打ち込んだものを用意しておき、そのデータで、T.TEST関数等を使って検定を行いました。

実際のデータとしては、店名は出さず、地域、タレ、種類、こってりorあっさり、掲載されていた価格をスプレッドシートで生徒に提供します。
これについてT.TEST関数やCONFIDENCE.T関数を使って実際に検定推定を行います。

様々なパラメータで試行錯誤の機会は広がったが、きれいな検定結果はなかなか難しい
実践を通しての振り返りです。
まず、こってりvs.あっさりや、豚骨vs.醤油など複数のパラメータを用意して、様々な組み合わせで検定を行えるように工夫したので、試行錯誤する機会を多くすることができ、生徒は主体的に自分で選んで課題に取り組んでいたと感じています。

ただ、検定の結果としては、やはりt分布に従っているという仮定がちょっと甘い部分もあって、棄却されるケースが少なかったかと思います。これは、リアルなデータでは検定結果がなかなかきれいに出ることがない、ということでは当然かと思いますが、今後このようなところを授業実践にどのように繋げるか、というところは課題であると見ています。
最後に一つ、お願いです。
今回の私の実践は踏み台のようなものであると思っています。
この発表では、やってみて今一つだった部分も含めて紹介しました。この記事をご覧いただいた皆様にも、ぜひ仮説検定の実践を行っていただければ幸いです。

神奈川県情報部会実践事例報告会2023オンライン オンデマンド発表より