












事例334
「社会に目を向ける」視点から学ぶデータの分析
日出学園高校 武善紀之先生

「情報I」の第4章「情報通信ネットワークとデータの分析」の「データの分析」は、数学との関連が大きく、数学の内容をどこまで扱うのか、「情報I」としての特徴をどのように出すのか、という授業の設計も難しいとともに、生徒も苦手意識を持ちやすい分野です。
今回は、日出学園の武善紀之先生の「データベース」と「データサイエンス入門」の2コマの授業を取材しました。
事例327「情報Iの授業で伝えたかったこと~情報技術と友達になって、『楽しみな未来』へ」(※1)で紹介したように、武善先生の3学期のテーマは、「社会と未来」です。ここでは、「社会をよりよくするデザイン」と「データ分析」を扱います。ここまで学んできた「情報」の視点で社会に目を向ける。その中の1つに「データ」がある、という位置づけです。
※1 https://www.wakuwaku-catch.net/jirei24327/
■社会に目を向ける~データはなぜ「21世紀の石油」なのか
世界はデータで回っている?!
前回までの「社会をよりよくするデザイン」では、身の周りにある小さな「わかりにくさ」「使いにくさ」に気づき、それをデザインによって改善する、という活動を行いました。
ここではUI(ユーザインタフェース)やUX(ユーザイクスペリエンス)といった考え方から、「情報の視点で社会を見る」とはどのようなことかを学びました。
今回は社会の仕組みとしてのデータベースを取り上げ、それを活用するデータサイエンスにつなぎます。キーワードはいずれも「社会」です。
データベースの授業の導入では、まず「身の回りにある様々なデータはどのように活用されているのか」という問いかけから、生徒たちが日常的に使っているATMやSuica 、e+(イープラス)なども、収集したデータを利用可能な形に処理して、必要なところに伝達する仕組みとしての「情報システム」であることに気づかせます。
例えば、コンビニなどでおなじみのPOS(Point Of Sales)システムは、実は「販売時点情報管理システム」であり、バーコードを読み取ることで、ただ金額を計算するだけではなく、その瞬間に販売記録が更新され、在庫管理や発注の自動化に利用されます。
ここで、先生は実際にバーコードリーダーでバーコードを読み込んで見せます。様々なデータがたちどころに表示されるのを目の当たりにすることは、まさに「情報の視点で社会を見る」経験となります。
ネットワーク(→2学期に履修済み)という「道路」の上を膨大なデータが飛び交って、文字通り「世界はデータで回っている」状況を作り出す。その裏で活躍するのが、データを1つにまとめて複数のシステムで共有できるようにしたデータベースである、ということを確認して、今回の授業ではsAccess(※2)を使ってこの仕組みの有用性を実際に経験します。
※2 https://saccess2.eplang.jp/saccess/

データベースに触れてみよう
sAccessは、選択・射影・結合などのリレーショナルデータベースの基本的な操作を簡易な日本語の命令文で実行して、命令の組み合わせによってデータの検索・抽出が行われる過程を観察することができる、オンラインのデータベース学習システムです。
「コンビニ」「レンタルショップ」「生徒名簿」「図書館」などのプリセットデータが準備され、ここから生徒の興味や授業の設計に合わせて使うことができます。今回の授業では、コンビニの売り上げを分析してみます。
sAccessにログインして、検索を行う手順は、先生が実演しながら進めます。この授業で一番大事なのは、欲しい結果を出すためにはコマンドをどのような組み立てにしたらよいか、「構造化」を考えながら手順を進めることです。「構造化」は、「情報I」の内容を理解するために通底するものとして、武善先生の授業の中では様々な形で取り上げられています(→事例327参照)。
「コンビニ」のデータセットには、商品コード、売上日、曜日、時間帯、性別、年齢層が入った「売り上げデータ」と、商品コード、商品名、内容量、メーカー、価格が入った「商品データ」の2つの表があります。商品ごとの売り上げを調べるためには、2つの表をつなぐ必要があります。このとき「商品コード」がキーになることに気づかせます。
このあと、「朝の時間帯にいちばん売り上げが多いものは何か」を調べるときの手順を、先生が順を追って説明します。そして、スライドの1~4の質問を自分たちで考えさせます。
先生からは、「データの山があっても、何から何を取り出すかがわからないと使えない。プログラミングと同じで、完全に自由に考えるのでなく、丁寧に順番を考えていこう」と指示が与えられます。コマンドの一覧がスライドに示されているので、行き詰まって困る生徒はほとんどいません。

※クリックすると拡大します。
欲しいデータを取り出すためには、おのずとコマンドの構造を取ることが必要になります。
sAccessは、日本語でコマンドを組むことができますし、ある程度の別名のコマンドも準備されているので、やりたい操作をスムーズにコマンドに置き換えることができます。さらに、SQLとも対応しているため、実際のデータベース言語との対応も可能です (※3)
※3 https://saccess2.eplang.jp/saccess/commandManual.php
質問1~4のうち、クラスの約半分が質問1ができたところでいったんやり方をチェックし、およそ半分が質問4まで終了したところで、手順を追って答え合わせをします。全てできた人は、自由にコマンドを組み合わせて分析を進めていました。

データベースを使う意味~「だから何?」を考える
ここまでの内容は、どちらかといえば「情報」ではなく、まだ「数学」の範疇と言えます。「情報」の役割は、出てきた結果を使って「だから何?」を考えることである、ということで、データベースの扱い方とともに、今回の授業のもう一つの柱の「戦略を考える」に入ります。
今回調べた売り上げ記録をもとに、このコンビニの売り上げを向上させる売り上げを増やすためには、どのような方針にすればよいかを、理由とともに考えます。
生徒からは、「朝・昼・夕に客が集中しているから、この時間帯に商品をたくさん入荷する」「よく売れている『さつまプリッツ』の仕入れを増やし、売れていないものは減らす」「金曜日は売り上げが減るから、定休日にする」等など、様々な意見が出てきました。
この分析を行うことで、コンビニの経営には「何となくこうなりそうだ」ではなく、データの裏付けのある戦略が必要であることを実感することができます。
ここまでの実践は、文部科学省「情報Ⅰ学習動画」としても公開されています。
※4 https://www.youtube.com/watch?v=T1UE1j8Q-i0

データベースの分析結果が社会を動かす
ここまでできたところで、教科書に載っているデータベースに関する知識事項を整理します。データベースはログを取ることもできること、DBMS(データベース管理システム)の機能や、データモデルの型、関係データモデルの各部分の名称など、今後データベースを本格的に学ぶ際に必要となる事項をざっくりと説明します。
ここにはあまり時間をかけず、世の中のデータの活用として一番身近なビッグデータの活用事例の話に入ります。
活用事例として先生が紹介したのは、ビッグデータの活用を取り上げたNHKの「クローズアップ現代」のVTRです。コンビニのポイントカードの利用者は4000万人以上で、利用件数は1日2500万件超。年齢や住所で個人が特定できてしまうこと、ポイントカードによる売り上げ分析で、実はシニア層でコロッケのリピート率が高いことが判明したのでシニア層狙う店では夕食時に揚げ物の品揃えを増やすことにしたことなどが紹介されています。
実はこの番組は2012年5月放送のものです。すでにこの時代からデータ分析の重要性に注目が集まっていたことに、生徒たちも驚きの表情を見せていました。
この他にビッグデータの分析がビジネスの可能性を広げた例として、「あるスーパーで紙おむつと一緒に買われる商品は○○○だった」「駅の自販機でリンゴジュースを主に買うのは○○○○○○である」という、マーケティングの有名な事例を挙げて、「紙おむつのコーナーの近くにビールを置く」「リンゴジュースのパッケージをサラリーマン向けのシックなデザインにする」などの戦略で売り上げが伸びたという話が紹介されました。
これらの事例が示すのが「データは21世紀の石油」、データ駆動型社会の姿です。
IoTによって収集される膨大なデータがAIによって整理・分析され、またAI自体も、大量のデータを学習することでさらに賢くなることで、これまでの社会の在り方を大きく変える仕組みや商品が生まれる可能性が生まれています。

※クリックすると拡大します。
一方で、「データとして扱われること」に対する倫理的な側面にも触れます。
先生が最後に紹介したのは、視覚、聴覚、位置情報などの全ての個人情報へのアクセスを許可する代わりに、生活全般が高水準で保障されるという近未来都市が舞台の小説です。高度情報管理社会の理想郷での幸福な暮らしには、実は「影」の部分もあって…という筋立ては、データによって全てを支配することには危うさもあることに気づかせます(※5)。
※5 「ユートロニカのこちら側 」小川哲(ハヤカワ文庫JA)
次回からは、より本格的にデータを分析する方法を学ぶ「データサイエンス入門」に入ります。また、今回の宿題として、日出学園の購買部の弁当販売データを分析することが課されました。
こたらのデータを使った授業は、武善先生が講師を務めたNHK高校講座「情報I」でも紹介されています(※6)。
※6 https://www.nhk.or.jp/kokokoza/jouhou1/contents/resume/resume_0000009467.html

■社会に目を向ける~データサイエンス
まずデータ分析の「型」を学ぶ
前回の「社会を回すデータベース」に続いて、より本格的にデータを分析する方法を学ぶのが「データサイエンス入門」の授業です。3回シリーズの授業の1時間目を見学しました。
前回の「データベース」で学んだように、今後の社会の仕組みは「データ駆動型社会」であり、「21世紀の石油」たるデータを利用するためには、それを扱うためのデータサイエンスのスキルが必要になります。

今回の授業では、このデータサイエンスの「型」を学びます。
ここまで学んできた問題解決は、PDCA(Plan-Do-Check-Action)サイクルで行ってきましたが、統計調査はPPDAC(Problem-Plan-Data-Analysis-Conclusion)のサイクルを回して進めます。
このD(Data)には「アンケート調査実習(自分たちでデータを収集する)」と「オープンデータの分析実習(オープンデータを使用)」の2つのやり方があり、前者は日出学園では「総合的な探究の時間」に行っています。
「データサイエンス入門」では、「とどラン」(※7)を使ってオープンデータの分析実習を行います。この実習は、アサンプション国際高校の岡本弘之先生の実践(※8)を参考に実施しました。
※8 https://www.wakuwaku-catch.net/jirei22205/
「とどラン」では、都道府県別に「国土・インフラ」「社会・政治」「文化・暮らし・健康」「娯楽・スポーツ」「店舗分布」「その他」の分類で様々なデータが公開されています。ここからまず自由に面白そうなデータを3つ探してみます。
例えば、「アイドルの出身地」のランキングでは、東京、大阪に次いで高知が登場します(※9)。これで生徒たちは盛り上がって、様々な検索をかけています。「とどラン」は、ランク別に塗分けた地図と、このアイドルのデータで言えば「総数」「人口10万人あたり」「偏差値」などの表が同時に表示されるので、特徴や傾向を直感的につかむことができます。
※9 https://todo-ran.com/t/kiji/24738
ある程度いろいろな検索をしてみて、ランキングの探し方に慣れたところで、先生から「(高校野球の)甲子園が強い都道府県ってどこだろう?」と問いかけがありました。予選が多くて、場数を踏んだ学校が強いのか。だとすれば、「高校数」と「甲子園が強い都道府県(=甲子園勝利数)」という2つのデータには関係があるかどうかを調べたら、関係がわかるね、ということで、今日から3時間の授業で「とどラン」を使っておもしろい関係性があるものを探して分析し、最後に発表する、という活動の流れが示されます。

各種統計指標の確認~数学Iの復習と、データの分析で必要な視点とは?
実際の作業に入る前に、数学Ⅰで学んだ各種統計指標の意味の確認を行います。ここで説明に使われるスライドでは極力数式を使わず、データの分布を軸として、それぞれの統計量の意味を直感的に理解できる工夫がなされています。

統計量の説明は、平均値と中央値から入ります。
年収の平均値と中央値と分布を示す有名なグラフを見て、平均値だけでは実際の傾向がつかめないことが一目瞭然であることを確認します。

※クリックすると拡大します。
次に、「数学も『情報』も平均点は60点、中央値も60点というテストがある。この2つのテストは同じ傾向なのか?」という質問が投げかけられます。
この例として示されたのがこちらの2つのグラフです。「情報」は得点が中央付近に集中し、数学は二極化しています。平均値・中央値が同じであっても、データの散らばりは全く違います。
この2つから、データを分析する際には、散らばりの違いが重要であることが示されます。

散らばりを図で示すのが箱ひげ図です。
箱ひげ図は中学校の数学で扱われ、「数学I」では既習事項とされていますが、その意味や見方を「ポイントはこれだけ」ということを簡単な図で確認します。

先ほどの「情報」と数学の分布のをヒストグラムを箱ひげ図で表すと、これだけの違いがあります。ヒストグラムと箱ひげ図の関係をつかんだ上で、さらに散らばりの傾向を数値で表すものとして、「標準偏差」があることが示されます。


ヒストグラムと箱ひげ図、標準偏差を1つのスライドにまとめたものがこちらです。

このように、平均と標準偏差はグラフの概形の目安となり、分布の様子や自分の位置がわかっていきます。
関連して、生徒が気になる「偏差値」を話題として取り上げます。100点満点で平均点が50点のテストで得点が70点だった場合、ばらつきによって偏差値がどのように変わるか、という4種類のグラフが示されました。そのスライドは、生徒たちも食い入るように見ていました。
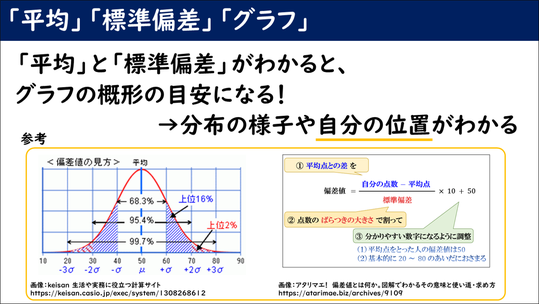
※クリックすると拡大します。
ここまでは単一のデータに関する指標でしたが、データを複数組み合わせると「関係性」=相関がわかります。この関係性を図で示すのが散布図です。

※クリックすると拡大します。
そして、2つのデータの相関の強さを示す数的指標が相関係数(r)であり、-1から1の値を取ることを確認します。その後、「今回の期末テストの『数学Ⅰ』と『情報I』の成績の相関係数は0.42だったんだけど、ここから何がわかるかな」と投げかけ、単に「正(負)の相関がある(ない)」だけでなく、ここまで復習したことを踏まえた上で、その背後にある関係性の意味について考えてみます。
この統計指標の説明は10分強ですが、身近な事例を使って、数式に踏み込まず指標の意味の理解が中心なので、生徒たちは集中して聞いていました。

※クリックすると拡大します。
とどランでおもしろい関係を見つけてみよう
ここからは、自分で「とどラン」から関係がありそうな2つのデータを見つけて、相関があるかを見る活動に入ります。今回の授業は、操作の方法を習得するために、いろいろ試してみることが中心です。
ランキングの一覧表をコピーして作業用のスプレッドシートに貼り付けますが、ここで使うスプレッドシートは、平均値や中央値を自動計算できるように予め準備されたものです。最初に先生が「人口」と「自動車の保有台数」で、データの貼り付け方や表記の修正(単位やカンマを除外する)といった加工の手順を実演して見せます。
2つのデータをそれぞれ加工して散布図を作成するシートに貼り付けると、散布図と相関係数が自動で表示されます。箱ひげ図はリンク先(※10)にデータを入力して作成させます。
表示された結果は、スクショしてスプレッドシートに貼り付けます。
※10 https://statistics.calculator.jp/basic/box-plot/

操作の手順はワークシートに書かれているので、自分でできる人はどんどん進めていくことができます。ついていけなかった人のために、もう1回別のデータで先生が実演し、その後は周りの人に聞いたり、挙手して先生に質問したりします。
データを選んだら、「仮説」「扱うデータ」「理由」をワークシートに書き、データを分析して結論を書いていきます。
生徒たちは、「体育館の数とバスケットボールの競技人口」「インスタント麺の消費とがん死亡率」「酒の生産量とおつまみの消費量」等など、楽しんで取り組んでいました。
最後に、先生から「客観的なデータをもとに説明すると、説得力が増す一方で、相関は強かったとしても本当にその仮説が正しいのか、ということも考えなければいけない」ということも投げかけられました。
次回は、4人1グループで今回の分析を行い、最後にグループ別に発表を行うことを予告して、1回目の授業は終わりました。

※クリックすると拡大します。
■データサイエンス入門」の着地点~「データサイエンス入門」2回目・3回目
次回の授業では、様々な「おもしろい関係」を探してクラスで共有し、相関関係の扱い方に慣れます。そして、次の第3回では、分析結果をさらに深掘りするべく、「今までの結論は本当に正しいか」ということを生徒に問いかけます。
ここでは、外れ値や直線以外の関係、擬似相関、交絡因子などについて幅広く扱います。1つ1つの要素を厳密に理解させるというより、一度考えた結論を見つめ直す意義について伝えることを重要視しています。
さらに、発展した分析手法としての回帰分析や、確証バイアス・選択バイアス・交絡バイアスなどPPDACの各段階で発生して、誤った解釈を導く「バイアス」の存在なども紹介します。
そして3回の授業の最後の着地点が、「コンピュータや統計をなぜ問題解決に活用するのか」という問いかけです。
問題解決の道具としてコンピュータ・統計を使いこなすのではなく、それぞれの長所・短所を知って補い合いながらよりよい未来に向かう、ということで、次回の「技術と人間の接点」の授業につながります。

[取材を終えて] ~「なぜ情報科を学ぶのか」と、「なぜ情報科で学ぶのか」
「情報I」の第4章は、情報化社会の基盤となる技術を扱う内容で、習得しなければならない専門用語やスキルが一段と多いところです。中でも「データの分析」は、数学Iで苦手意識を持ってしまった生徒には、最初からハードルが高く感じられるところでしょう。
今回の「データベース」と「データサイエンス入門」の授業では、基本統計量や相関係数など、数学の内容の説明もありましたが、ほとんど数式は使わず、その意味を理解することに重点が置かれました。
そこでは、「基本統計量や分析のための計算は全てコンピュータがやってくれるので、欲しい結果を出すためのコマンドの構造化を考えたり、出てきた結果から何が言えるか・何ができるかを考えよう」という、「人間の役割」の活動が中心になっていました。
今後、データを「21世紀の石油」として活用していくためには、数学の演習の題材のような手計算やペーパーベースで扱えるレベルとはまさに桁違いのデータ量を扱わなければなりません。
そこでは、おのずと「コンピュータに任せられること・任せなければならないこと」と「人間ができること・やるべきこと」の役割分担を考えることが必要になります。
その意味で、「データベース」の授業で出てきた、全てのデータが管理される社会の倫理的な問題も、「データサイエンス入門」の最後に扱われるバイアスの問題も、数学ではなく「情報I」の授業だからこそ扱えることを強く感じました。