












事例376
生徒たちが感じたPythonによるデータ分析のメリットとデメリットについて
神奈川県立横浜国際高校 鎌田高徳先生

今回は、「生徒たちが感じたPythonによるデータ分析のメリットとデメリットについて」というタイトルでお話しします。
最初に自己紹介です。横浜国際高校の鎌田です、情報科の教員として神奈川県に採用されて、15年目になります。毎年実践事例報告会の運営と発表をさせていただいております。今年はデータサイエンスに踏み込んでみました。

「情報Ⅱ」の「情報とデータサイエンス」では、学習指導要領には「多様かつ大量のデータを活用する有用性に着目し」とあります。ここではデータを活用することの有用性に気づかせたい、ということですね。
今回は、この大量データのオープンデータを、ExcelではなくPythonで分析する際に、どのような手順で行って、それに際してどんなトラブルが発生し、それを解決するためにどういった授業の設計をしたのか、ということについて報告します。この事例にしたのは、プログラミングによる大量のデータ分析を授業で扱っている事例が少ないと感じていたからです。

※クリックすると拡大します
多様かつ大量のデータをPythonで扱う意味は何か?
この授業のそもそものきっかけは、文部科学省の「情報Ⅱ」の解説動画(※1)で、武善先生と春日井先生が出演されている「情報とデータサイエンス」の授業展開例です。全てが実社会・実生活と関連したすばらしい授業実践となっていますので、ぜひご覧になってください。
※1 https://www.nttls-edu.jp/joho/

※クリックすると拡大します
今回の授業をする上では春日井先生の事例(※2)を特に参考になりました。
多様かつ大量のデータを扱うための作業として、オープンデータを整形する部分と、活用する有用性を考える部分があります。
「情報Ⅰ」のデータ活用やプログラミングによるシミュレーションを、Excelや表計算ソフトで済ませればいいじゃないか、という方もいらっしゃるかもしれませんが、なぜExcelでなく、プログラミングで扱うのか、ということを生徒たちと一緒に試行錯誤しながら考えてみた、というのが今回の実践です。
※2 【情報Ⅱ】情報とデータサイエンス・重回帰分析を用いた予測「睡眠時間を他の行動時間から予測
しよう」(youtube)

※クリックすると拡大します
コンサルタント会社の社員になって、データに基づいたプロジェクト提案書を作成する
授業は全部で10回ですが、今回はこの第1回から第4回の、手法を学ぶ部分を報告します。この授業に入る前に、Pythonの基礎的な部分を学ぶ授業を5回行っています。
この授業では、「政府や企業、自治体など大きな組織を動かすためには、膨大なデータを分析してクライアントを説得する必要があるよ」ということで、政府や企業にプロジェクトの提案をするコンサルタント会社の社員になって、グループごとにデータに基づいたプロジェクト提案書を作ろう、という設定にしています。

まず扱うデータです。学習指導要領にも「多様かつ大量なオープンデータを活用する」と書かれていますが、実はこれをいじること自体が大変です。生徒が自主的に活動するとより大変になります。

※クリックすると拡大します
データはSSDSE(※3)とe-Stat(※4)を使いましたが、いきなりe-Statを使うのは、敷居が高いと感じました。そのため今年の全高情研全国大会(愛知大会)で佐藤義弘先生が発表されているように(※5)、教育用標準データセットのSSDSEを使われることをお勧めします。
※3 https://www.nstac.go.jp/use/literacy/ssdse/
※5 https://www.wakuwaku-catch.net/jirei24338/
実は私がこの授業をしたとき、最初はe-Statから入ったのですが、生徒にe-Statからデータの整理をさせると、非常に大変そうでした。ですから、e-Statを使うのであれば、まずSSDSEで何回か演習した後でやった方がよいというのが、今回授業をした経験からのお勧めです。

■SSDSEの家計消費データから箱ひげ図を作ってみる
それでは、箱ひげ図の作り方からやっていきましょう。
今回は、いろいろな食品の家計消費のデータを使ってみます。SSDSEのトップページにある「最新版のSSDSE」から「SSDSE-家計消費(SSDSE-C)」(※6)のcsvファイルをダウンロードして、整形していきます。
※6 全国・47都道府県庁所在市×家計消費226項目

※クリックすると拡大します

※クリックすると拡大します
ここがけっこう大変です。ここでは、米、食パン、生うどん・そばの都道府県別データを使って箱ひげ図を作るので、まず不要なデータを消していく作業が必要になります。
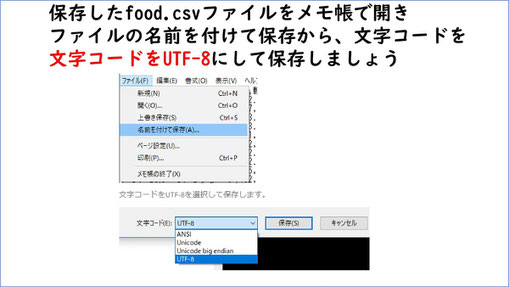
必要ないデータを削除したものを「food.csv」でいったん保存します。保存する際には、文字コードに注意が必要です。

その後Google Colaboratoryに先ほどの「food.csv」をアップロードします。アップロードした後、プログラムを実行して、読み込んだデータを呼び出せることを確認します。
※クリックすると拡大します
その後、この3つのデータを使ってPythonで箱ひげ図を作ります。最初に、米と食パンの2つだけで書いてみます。さらに、3つのデータを使って、日本人の食生活について仮説を立てて比較する、ということを行っています。

※クリックすると拡大します
Pythonのプログラムのデータはこちら(※7)です。
※7 箱ひげ図作成のPythonのプログラム
具体的な手順は動画をごらんください。
■箱ひげ図で成型したデータで相関分析をやってみる
続いて、相関分析をやってみます。相関分析も、先ほど成形した「food csv.」のデータをそのまま使います。
データを読み込んだら、まず日本語対応のためのライブラリを読み込む作業を実行します。その後、ライブラリをインポートして、先ほどアップロードしたfood csv.のデータを読み込んで、相関係数を求めます。
まず3つのデータで相関行列を作ります。このような形で作ることができます。

※クリックすると拡大します
相関分析のプログラムのデータはこちらです(※8)。
※8 相関分析のPythonのプログラム
ここから相関ヒートマップを作ることができます。さらに、3つ以上のデータで散布図行列を表示させることもできます。

※クリックすると拡大します

※クリックすると拡大します

※クリックすると拡大します
生徒たちの反応としては、Excelで作るよりも見やすいという意見が圧倒的に多かったです。
手順は動画をご覧ください。
■e-Statのデータで単回帰分析&重回帰分析
最後は単回帰分析です。ここではe-Statのデータを使って、春日井先生の動画で取り上げられていた、「睡眠時間を他の行動から予測しよう」(※9)をやってみます。
※9 https://www.nttls-edu.jp/joho/

※クリックすると拡大します
こちらもデータの整形を行う必要がありますが、やはりこの作業はとても大切です。
こちらの手順を動画で見てみましょう。途中で生徒がよく躓くところも出てきます。

※クリックすると拡大します
単回帰分析のプログラムがこちらです(※10)。
※10 単回帰分析のプログラム
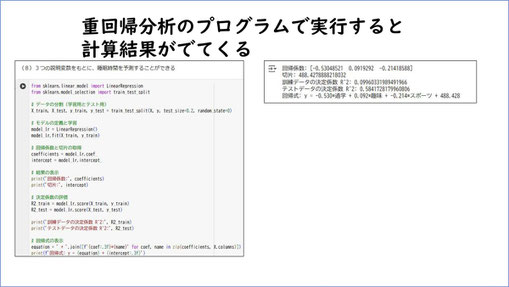
続いて、重回帰分析をやってみましょう。
※クリックすると拡大します

※クリックすると拡大します
手順はこちらです。(※11)
※11 重回帰分析のプログラム
Pythonのメリット~簡単・速い・わかり易い・楽しい!
この4つのPythonによるデータ分析が終わった後、生徒たちにアンケートを採りました。
アンケート結果がこちらです。生徒の自由記述の回答を生成AI使って分析してみると、Pythonによるデータ分析のメリットは、大きく分けて5つになりました。
まず、迅速なデータ処理ができること。生徒たちは、「Excelでも速くて便利だったけど、Pythonは圧倒的に速い」「こんなものがあったんだ、と感動した」という声が上がりました。
また、Pythonはグラフを簡単に作ることができる」という声も多かったです。データの整形が必要ではありますが、グラフが簡単に書けることは非常に良かったと言っています。
さらに、相関分析の分析が効率的にできること。相関行列、散布図行列で一気に見ることができるので、とてもわかり易かった、という声がありました。
また、私が思うよりエラーの修正が容易だと感じていたようです。あとは、「やっていて楽しかった」という意見がメリットとして挙げられます。

※クリックすると拡大します
Pythonのデメリット~エラーの原因がわかりにくい、環境依存性が大きい、やはり整形は大変…
でも、圧倒的にメリットの方が大きい
一方、デメリットとしては、まずエラーが出たときなどに、プログラムのコードの意味が分からない、ということがありました。
実は私も今回、春日井先生の授業動画見て、自分でコードを組んでみて、分からないところはかなり生成AIの手助けを借りています。私自身、やってみて難しかったので、基本的にプログラムは私が作ったものを配布して、生徒たちはデータを整形して、実行する作業だけとしました。ですので、今回ご紹介したプログラムも、改善できる点があるかと思いますので、ぜひご指摘いただきたいと思います。
このエラーの問題と、3つ目の環境依存性の問題は、実際授業の場面でも大きかったです。本校はBYODなので、生徒の端末の環境がばらばらです。そのため、デバイスによって、実行可能なプログラムとそうでないものがあり、周りの人は同じようにやってできたのに、自分の端末ではできない、ということがあって、ここは結構大変でした。
そして、やはりデータの整形の大変さということが、デメリットとして挙がりました。実際に作業にかける時間は、やはり大きな問題ですので、私自身も今後経験を積んで改善を図っていきたいと思います。
ただ、今回の振り返りを見ると、やはりメリットを挙げた意見の方が圧倒的に多かったです。皆さんもぜひPythonを使ったデータサイエンスの授業を一緒にやっていきましょう。

※クリックすると拡大します
なお、発表後に大阪大学の北村祐稀様より、下記の2点のアドバイスをいただきました。次回の実践につなげていこうと思います。北村様、ありがとうございます。
■CSV ファイルの文字コードについて
df = pd.read_csv('data.csv', encoding='shift_jis')
のように文字コードを指定してあげると、Shift_JIS のままでも問題なく動作するかと思います。
参考記事)https://relaxing-living-life.com/51/#google_vignette
■グラフを作る際に日本語が使えない問題について
import japanize_matplotlib
と最初に書いてあげると、日本語を使用しても問題なく動作するかと思います。
参考記事)https://qiita.com/uehara1414/items/6286590d2e1ffbf68f6c
神奈川県情報部会実践事例報告会2024オンライン オンデマンド発表より