












高校教科情報シンポジウム2017秋 ― ジョーシン2017秋― 講演
人工知能を利用した記述採点支援システム
大学入試センター 研究開発部 石岡恒憲先生

大学入試センター試験に代わる新しい試験が平成32年から実施されますが、そこで目玉になっているのが、自由記述式試験の導入です。今回は、そのコンピュータを使った採点システムに関してお話しいたします。また、大学入試センターでは、人工知能を利用した採点技術の支援についても研究を進めていますので、そちらについてもお話しします。
さらに、全米学力調査(NAEP:The National Assessment of Educational Progress)では、記述式試験がコンピュータで実施されています。その解説をいたします。
記述試験の二つのタイプ

記述試験には、大きく分けて二つのタイプがあります。一つはエッセイ(小論文)タイプと呼ばれる、与えられたトピックに沿って自由に書くもので、日本語で800字から1600程度、英語では500ワードから600ワード程度のものです。
エッセイには正解がないので、次のような観点で評価します。一つ目が修辞、これは文章巧さや語法の使い方です。二つ目が論理の進め方や掘り下げが十分できているか、例示がきちんとできているかといったこと。三番目が内容で、質問文に十分に答えられているかどうかということを評価します。
エッセイの採点については、欧米では現在E-raterやIntelliMetricというシステムが、実際に公的な試験の採点で使われています。これらは、人の評価に十分に近いという多くの実証があります。
記述試験のもう一つのタイプが短答式(Short Answer)と呼ばれるもので、こちらは望ましい正解があるものです。したがって採点は、正解文と実際に書かれた文が同義であるかを判定することになります。分量は、1~2文です。
TOEICやTOFEL、アメリカの大学入試のための共通テストであるSATなどの試験を行っているETS(Educational Testing Service)という世界最大のテスト機関が、c-raterという採点システムを作っていますが、実際の試験ではまだ使われていません。
正解文と同義かどうかを判定する技術は、含意関係認識(Recognizing Textual Entailment)といって、現在、自然言語処理の分野で最も熱いトピックとして、研究が急速に進んでいる分野です。
世界的なエッセイ評価システム
エッセイ評価については、2012年に、ヒューレット財団がスポンサーになって、国際コンペが実施されました。これは、優勝金額が10万ドル、日本円で1000万円くらいの非常に大規模なものでした。
このコンペに招待されたのが、下図のAutoScoreからIntelliMetric までの9機関です。この中で一番有名なのが、先ほどご紹介したETSが作っているE-raterV.2です。これはTOEICやTOEFLのライティングの試験に実際に使われていますが、機械が採点を全部行うのというわけではなく、機械と人間がそれぞれ採点し、人間と機械に違いがあるときは、もう一回また人間が採点するという、人間の採点の手間を半減させる目的としての使われ方です。手法としては、重回帰モデルに基づいています。
この分野の自動採点の一番古いものが上から6つめのPEGで、これも重回帰モデルが使われています。その後に出たのがIEAで、LSI(Latent Semantic Indexing)、統計でいうところの特異値分解を行い、言語の単語空間での意味的な近さを見て、きちんと答えられているかを見る仕組みになっています。
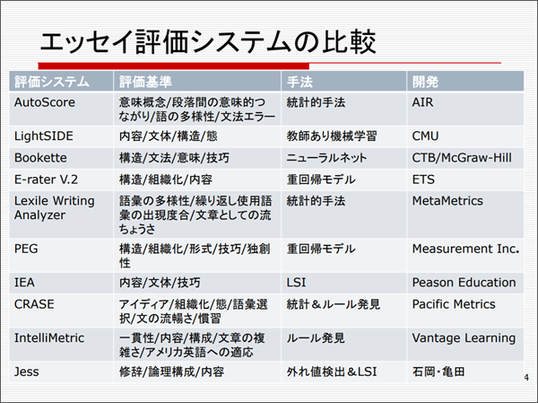
初めはこのような統計的なアプローチから始まりましたが、その後出てきたもので比較的有名なのがIntelliMetricで、いわゆるAI、機械学習を使ったルール発見に基づくアプローチを用いています。このような新たなアプローチと従来からある統計のシステムが、いろいろ組み合わさったり、融合したりというのが、現在の採点システムの主流になっています。
PEGやIEAといったシステムは、初期の頃は研究者が個人で作っていましたが、その後Peason EducationやMesurement Inc.といった大きな会社がスポンサーに付きました。今は、こういった採点ビジネスが大きなビジネスとして成り立っているようです。
日本で開発のエッセイ評価システムJess
日本語の評価システムとしては、上記の表の最下段の、我々が作っているJessがあります。統計で言う外れ値検知とLSI手法として使っています。

Jessの評価基準自体は、ETSのE-raterを参考にして三つの観点から採点しています。
一つ目が修辞、文章が読みやすいか、様々な語彙が使われているかなど、文章がよく書けているかということです。エッセイであれば、ある程度専門用語のような難しい言葉が入っていないと評価が低くなります。欧米語の場合は、こういった長くて難しい単語をビッグ・ワードと言いますが、日本語では漢字にするとかえって言葉が短くなるので、単に長さだけでなく、読みの長さでそれなりに難しい単語かどうかを判定しています。その他に、受動態の文が多すぎるのはよくないといった、一般に言われる「良い文章の書き方」なども指標に入れて評価します。
二番目が論理構成です。例えば、接続表現で言えば、ある文章に対して逆接が2回も3回も続くような文書は、論理の進め方としては良くないわけで、自然な流れのわかりやすい構成になっているかということも見ていきます。
三番目が内容です。問題文に関連した語彙が用いられているかを見るために、当時のWeb検索技術LSIを実装しました。プロの書いた文章を見て手本として、それと比較して書き方がおかしくないかということを見るという手法を取りました。
手本としたものは、当時電子媒体で公開されておりました毎日新聞の社説やコラムを使って学習しました。語彙については、新聞の数年分の全記事を入れて、統計学的な異常値検知でデータを見ました。
以前は、入試センターが自前でサーバーを立ち上げて、そこに採点システムを載せていましたが、万一これがウイルスなどで攻撃されたりすると大変なことになりますので、セキュリティを考えてレンタルサーバーに移行しました。ただ、公的機関のサーバーの記事は、Google検索でランクが上に出ますが、レンタルサーバーはランクが下になるため、移行後利用者が多少減ってしまったということはありました。

Jessの実証実験が、民間会社や大学に協力いただいて、実証実験が行われています。実験結果から、採点のバラつきがかなり圧縮されるということが明らかになりました。専門家同士でも当然採点はバラつきます。専門家同士のバラつきより、採点システムと専門家の間のほうがバラつきが小さく、その点では採点システムもそれなりに使えると思われます。ただ、問題や選んだトピックによっても一致度合いは異なるようです。
残念ながら、現時点では大学入試ではまだ使われておりませんが、平成32年には某国立大学のAO入試試験で導入することになっており、開発もいろいろ進んでいます。
短答式記述の同義の判定

さて、新テストで問題になると思われるのが短答式記述試験で、ここで使われているのが、含意関係認識です。これは、簡単に言えばt1、t2という2つの文章を与えて、t1が成り立ったときにt2が成り立つかを判定する技術です。
例えば、t1として「鎌倉幕府は1192年に始まったとされていたが、現在では実質的な成立は1185年とする説が支配的だ」という文章があります。これは教科書に書かれている文章です。一方、t2として「12世紀に日本では鎌倉幕府が開かれた」という文があります。これは、センター試験の世界史や日本史で大半を占める、正誤問題の選択肢に相当する文章です。我々なら、t1ならばt2が成り立つことはわかりますが、機械でやらせようとすると、実は結構大変です。
まず、t1から「鎌倉幕府が1185年に成立した」ということを読み取る必要があります。この文章は複文になっていて、後ろの文章の実質的な主語は、前の文章に出てくる「鎌倉幕府」です。一般に複文だからといって、後ろの文章の主語が前の文章の主語をそのまま継承するとは限りませんので、個別に判断する必要があります。さらに、1185年というのが12世紀であること、「成立」と「開かれた」が同じ意味だということが理解できなければなりません。

このように、こんな単純な文章でも、人工知能にとっては結構難しいわけです。国立情報学研究所が平成28年度まで行っていた、有名な「ロボットは東大に入れるか」プロジェクト(東ロボプロジェクト)でも、この含意関係認識技術を使って問題を解こうというアプローチを試みていましたが、実はなかなか苦戦していたのです。
では、どんな解き方ならうまくいくのでしょうか。3年前まで、一番有効とされていた方法が、「うそキーワード」方式です。これは私が名付けたものですが、選択肢の中のうそのキーワードを見つけ、それによって間違った文章を見つけるというアプローチです。
その次の年は、さらに賢い方法が考案されました。海外の大学も参加してコンペを行った中で、日本ユニシスが作ったアプローチで、世界史は100点満点中76点と、非常に良い成績を収めました。これは、まず前提として固有表現の辞書や、単語の上位・下位の認識技術を踏まえた上で、次の三つの手法を組み合わせるものです。
一つは、質問応答で解くものです。自然言語の世界では、質問応答システムの研究はかなり進んでいるのですが、これは間違った文章を見つけるのに有効だということがわかりました。
二つ目が構文木のマッチングで解く方法です。これは言語処理の文法を考えた非常にオーソドックスな方法ですが、これは正しい文章をきちんと見つけるときに適用できます。もちろん、適用できないこともありますが、うまくいくときには100%正しいものがわかるという方法です。
三つ目が、単語の共起確率で解くものです。一まとまりの記事の中で、二つの単語が同時に出現することを共起効果と言い、それらの単語が意味的に非常に似た概念、あるいは近い関係にあることがわかります。その共起が起こる確率で解くという方法です。この共起確率は二つの単語のペアしか見ていないですが、非常に適用範囲が広いので、ベースラインを保証するという意味ではうまく使えます。
これらを併用すると実際かなりいい成績が取れているのです。

それぞれの解き方を具体的に説明しましょう。
一つ目の質問応答で解くというのは、例えば「15世紀、ヘンリ7世がテューダー朝を開いた」という文章があった場合に、固有名詞を隠して、
1. ヘンリ7世がテューダー朝を開いたのは『いつ』ですか。
2. 15世紀ヘンリ7世は『どういうNation』を開きましたか。
3. 15世紀に『誰が』テューダー朝を開きましたか。
という質問応答にかけて、隠した部分が正しく出ているかを判断して誤文を見つけます。

三つ目の共起確率では、例えば「第一次大戦中にロシア革命が起こって、ニコライ2世が退位した」といった固有表現や年代などをピックアップして、例えば「起こり」という動詞を「生じる」「始まる」といった同義語表現に置き換えても共起しているか、また「退位」はどうか、「第一次大戦中」はどうか…と、キーワードがうまく共起しているかどうかを調べます。そして、共起しないものが出ていると、この文章は間違いとわかるというものです。
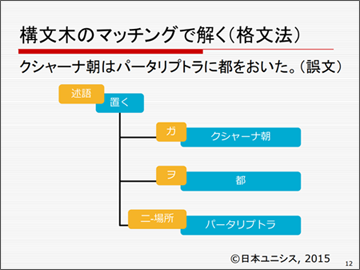
二つ目の構文木のマッチングで解くというのは、自然言語の世界では「格文法」と呼ばれているものです。意味解釈の中心に述語を据えるというものです。
例えば、「クシャーナ朝はパ-タリプトラに都をおいた。」という文の場合、「置く」という動詞が述語に相当し、「クシャーナ朝」が主語(主格:「ガ格」)に相当します。「都」は日本語の場合で「ヲ格」、また、場所は「ニ格」となります。このように、動詞を中心に据えてガ格・ヲ格・ニ格に相当するものを選ぶわけです。
そして、教科書で書かれている文章も同様に格文法に照らして、「ガ格とヲ格は一致しているが、ニ格が一致していない。つまりこの文章のここが間違いだ」といったことを見つけます。自然言語では「一致している」ということを見つけるのは難しく、排他、つまり「起きないことをもって一致してないと見なす」というのが普通のアプローチであるようです。

それでも100点満点中76点です。非常にいい成績ではありますが、実際の採点に使うには、精度が低く、採点を100%機械に任せるのはまだまだ難しいということになります。
短答式記述試験の自動採点システムJS4

もっと難しいのが、短答式記述式試験の採点です。大学入試センターではJS4という採点支援システムを作っており、これは国語や社会などの、30~60字程度の文章で書くものを想定しています。
GoogleやMicrosoftなどが莫大なお金をかけて精度の高い質問応答システムを作ろうとしていますが、なかなかうまくいっていません。コンピュータの限界としてよく例に出るのが、スマホアプリのSiriに「この辺りでおいしいイタリアンレストランは何?」と聞いても、「この辺りでまずいイタリアンレストランは何?」と聞いても、同じお店が出てくるというものです。質問の意味を正しく理解しているのではなくて、キーワードだけをぴぴっと選んで、膨大な検索技術で取ってきているからです。
したがって、たくさんの優秀な方が同義や含意、推論などの正確な判断の研究を進めているのは事実ですが、試験の採点に使うには、ここ数年では無理だろうと考えています。ですから、自動採点を導入するのであれば、まず基本的な採点基準をベースにして、その適合をシステムがある程度自動判断する。また、機械学習もかけて、推奨値といったものを提案する。人間はその数値を確認し、ズレが出たら適宜修正して、最終的に人間が確定点を与えるといった使い方が、現実的な落としどころではないかと思います。
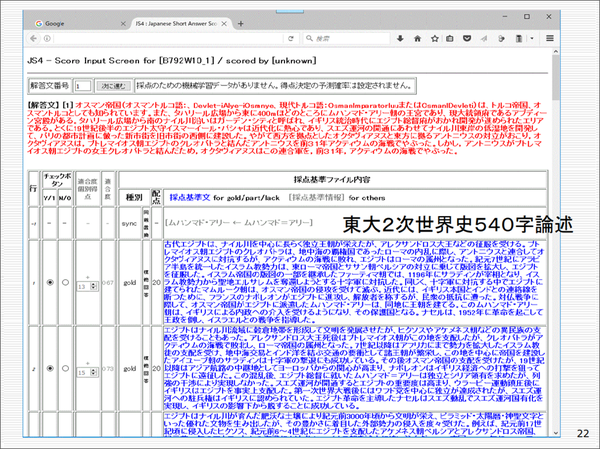
下図は、今、我々が作っている採点システムの画面です。世界史のアッバース朝の税に関する問題で具体的に解説します。解答者の記述「シズヤとハラージュを両方とも収めなければならなかったのが、アラブ人と同じでハラージュだけ収めればよくなった。」に対して採点基準に合わせて採点していきます。
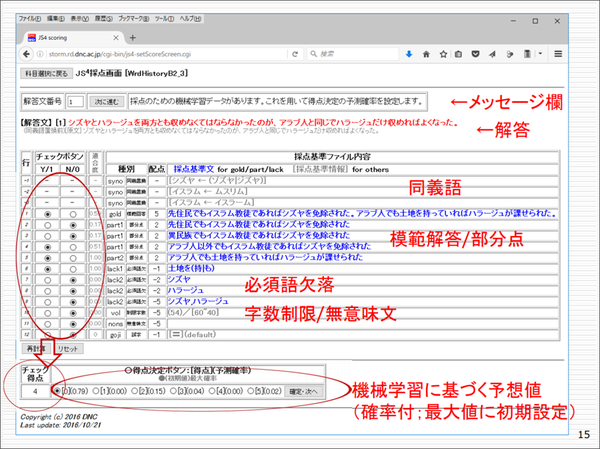
※クリックすると拡大します。
まず、模範解答との適合度をある程度数値化します。模範解答が複数ある場合は、一番適合度の高いもの、つまり最高点を採用します。模範解答は、「先住民でもイスラム教徒であればジズヤを免除された。アラブ人でも土地を持っていればハラージュが課せられた」です。これはどういうことかというと、イスラム教徒であれば、今まで課せられていたジズヤ(人頭税)は免除になる。一方、ハラージュ(地租)に関しては、非ムスリムに対して免除だったものが課されるようになった、という二つが書かれていなければならないわけです。
部分点についても採点基準があり、その適合を見ます。さらに、必須語が欠落したら減点、字数制限や誤字・脱字による減点、無意味な文章があれば減点といったように、採点していきます。
もう一方で、機械学習がはじき出した予想値を0点から5点までそれぞれ確率付きで示し、その数字を見て、人間が最終的に後ろの確定ボタンを押して決める。機械が採点したもののままで良ければ、この「進む」ボタンを押してどんどん先に進む、というものを考えています。
この自動採点の試行に用意したのが、上記の問題も含め、以下のような問題です。20字から60字程度を書いて、それぞれ3点から6点の配点となっています。


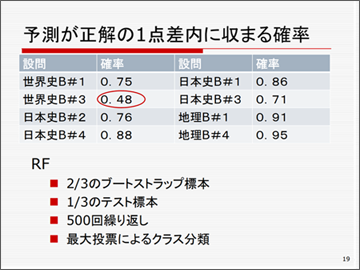
上記の8つの例題で、予測が正解の1点差に収まる確率がこちらです。アッバース朝の税の問題はかなり難しく、0.48でした。しかし、それほど複雑でなければ、そこそこの予測をできるデータのレベルにはなっています。
機械学習には、ここではいろいろなアプローチがありますが、ランダムフォレストと呼ばれている方法を用いています。このあたりは少し専門的なお話になりますが、2/3のブートストラップ標本を使って500回繰り返し、最大投票によるクラス分類を行っています。
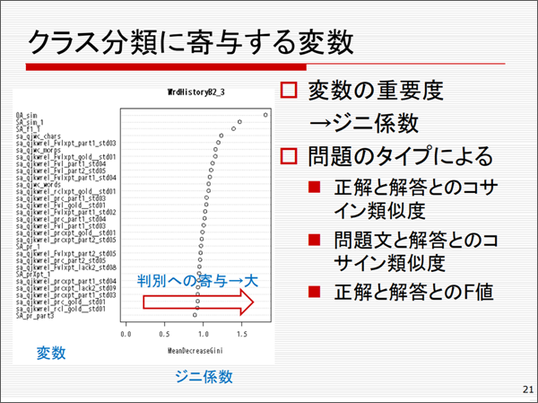
ランダムフォレストを使うのは、採点がブラックボックスにならないようにするためです。今はやりのディープラーニングで採点すると、なぜその採点になったのか説明がつきません。ランダムフォレストは、いわゆる分類比による判定ですから、クラス分類するのに、どの変数がどのくらい利いているかということが定量的にわかります。分類の影響度を示す指標として、よく経済学で使うジニ係数を使います。
クラス分類にどのような変数が寄与するかを調べたのが下図です。問題のタイプによりますが、正解文と解答文のコサイン類似度が大きく効くようです。これは、文章を多次元ベクトルで表したときに、二つのベクトルのなす角のコサイン、余弦で表したもので、統計でいうところの相関係数です。その他に、問題文と解答のコサイン類似度や正解と解答のF値(情報検索で用いられている指標)あたりが寄与度が高いことがわかっています。
自動採点システムJS4で500字の論述問題の採点
先ほどの自動採点で扱う記述問題は30字から60字くらいのものを想定していますが、「東ロボプロジェクト」では、コンピュータに東大の2次試験の論述問題の解答を作成するということをコンペとして行っています。東大の世界史の二次試験は、非常に大きいテーマについて8個程度のキーワードを必ず入れて500字程度で論述するものです。キーワードが指定されているのでエッセイほど自由度はなく、書かれる領域も決まってきますので、JS4のショートアンサーの記述の採点が、500字の論述の採点にどれくらい適用できるかを見てみました。
下図の赤字部分が、東ロボの解答ですが、教科書の該当する記述を適当に寄せ集めて、文章要約の技術を使ってうまく指定の文字数に収めて書いたものです。実際の模範解答は3通りあり、それぞれとの適合度を見るわけですが、模範解答の他に部分点を与えるところが20~30項目あり、人間が採点するとなると、かなり大変だろうと思います。
※クリックすると拡大します。

今年12月に国立情報学研究所で、NTCIR13(※)という国際会議があり、今回は9つのタスク(研究分野)でコンペ型の発表が行われます。我々大学入試センターチームは、実世界質問応答を目指すQA-Labタスクというところに参加します。国内外合わせて9団体が参加することになっています。テーマは、今お話しした世界史の大学入試問題のような、長い分量である程度の正解のある記述です。
我々のチームのシステムは、今のところ20問中16問が、20点満点の3点以内という成績です。ただ今の時点では、得点が低いのでまだ妥当性の評価はできていない、というところです。
※ NTCIR13(NII Testbeds and Community for Information access Research)
http://research.nii.ac.jp/ntcir/ntcir-13/conference-ja.html
新しい共通テストでは、国語で80字から120字くらいの自由回答が想定されているようですが、実際の現場でも、このあたりの問題が一番需要があるのではないでしょうか。機械には採点の手間と、採点者によるバラつきを軽減させるという部分のサポートを期待しています。ですから、これが実用化して、記述回答全般を採点支援できれば、新テストに限らず様々な試験で使えると思います。
NAEP(全米学力調査)における記述式試験
三つ目のトピックが、NAEP(全米学力調査)における記述式試験です。従来ペーパーテストで行われていましたが、最近はCBTが盛んになってきています。2011年に作文テストも初めてコンピュータによって実施されました。それについてご紹介します。

NAEPは、全米約2000の学校から10万人に対して行われるサンプリング調査です。日本の学年で言えば、小学校4年、中学校2年、高校3年で実施されます。
NAEPは大きく二つに分かれます。一つは、社会や時代の変化に合わせて、その時々の教育課題に応じて行うMain NAEP。作文のようなマイナーな科目は6~7年おきくらいです。2017年には実施していますが、結果はまだ出ていないので、直近が2011年実施のものです。
もう一つが、四則演算やスペルなど、時代の変化にかかわらず必要な基礎学力を問うLong-term Trend NAEP。この二つを組み合わせて実施しますが、希望する州があれば、Main NAEPをサンプリングではなく、もっと大規模に行うこともできる仕組みになっています(State NAEP)。

基本的には、紙と鉛筆によって行う試験ですが、実施団体のNAGP(National Assessment Governing Board)はコンピュータによる評価を指向しています。2011年には完全な形でコンピュータによる作文試験が行われました。数学の問題ではいわゆる適合型テストが採用されました。適合型テストとは、正解か不正解かによって、次に出てくる問題が変わるタイプのテストで、これによって時間を短縮するとともに、ある程度の推定精度を得ることができます。
NAEPの作文のチュートリアル・ビデオは以下をご覧ください。
https://www.youtube.com/watch?v=NEhS2x2pvB4

注目されるのがユニバーサルデザイン、障害者に対する配慮です。出題文の音声読み上げやフォントサイズの変更、マーカーボタンで地色を変えるということもできます。NAEPは、障害者に対しても代替問題を使用せず、同じ問題を解答させることを基本としています。公平性を担保するとともに障害者の尊厳を損なわないという考え方からです。
また、コンピュータを使うことによって、作題や採点の手間を大幅に軽減することができています。
コンピュータ化というのは、当然のことながら時代の趨勢で、今回の新テストの記述試験もコンピュータによる自動採点の導入は避けられない課題であると思っています。
今日お話ししたことを含めて、電子情報通信学会誌vol99(2016年(※))に詳しい内容を掲載しています。オープンアクセスですので、ぜひご覧ください。
※ http://www.journal.ieice.org/summary.php?id=k99_10_1005&year=2016&lang=J
[質疑応答]
質問1(大学教員):記述式の問題を機械学習で採点をするには、模範解答など学習をするためのデータが膨大に必要になるかと思いますが、どういったものを用意されていますか。
石岡先生:センター試験のように何十万人も受験するということを考えると、レベルの高い採点官 を多数揃えることは不可能です。ですので、あらかじめ採点のプロのような方に模範となる採点の仕方を作っておいていただければ、その後は機械学習で学習させて、採点をしていくことになります。
実際の採点は1日では終わりませんので、プロの方のデータを使うのと同時並行で、さらに組み込めるレベルの解答とそうでないレベルのものを分けて、信頼に足りる解答はどんどん採点システムに組み入れていくという使い方をしていくことを考えています。
質問1’(大学教員):そうすると、機械は試験が終わってから採点をしながら学習をしていくというイメージでよいでしょうか。
石岡先生:はい。本当は、初めに専門の採点者があらかじめ模範を作って、あとはそれに準じて採点するのが制度的にはいいのかもしれませんが、実際はなかなかそういうことは難しいと思います。
質問2(大学教員):人工知能が人間と同じように採点するのが非常に難しいというのは、きょうのお話でわかりましたが、例えば短文を書かせる場合に、必須の語句がなければ減点するというくらいの採点基準を作って機械化してしまえばよいのではないかと思いますが、そういったことはできないでしょうか。
石岡先生:採点基準をいかにうまく、機械にもわからせる形で作るかというその兼ね合いが、キーになると思います。要は、採点基準を作るのがコンピュータの専門家でない方であっても、簡単に作れて、すぐに採点画面に反映できる、というところがポイントになると思います。
質問3(大学教員):今日お話をうかがっていると、文字で記述していくことが基本的でしたが、例えば数式を数学的に解釈して正しいかどうかという採点の仕方もあれば、数式を文字として見て、マッチングさせるというのもあると思います。
特に数学では、表現が変わっていても実は同じ数式とかいうのもありますし、情報でも、そういう数式を書かせることがあります。変数にしても、例えば数学だと1文字で変数ですが、情報だと2文字、3文字の変数もありますよね。その辺りはいかがでしょうか。
石岡先生:実は、自動採点については数式は全くやっていません。基本的には国語と社会科だけを想定しています。最近はキーボードが打てない学生さんが結構いますので、現段階では手書きになりますが、まだ、手書きを機械で文字認識するのも難しい状況です。数式はそれが特に難しくて、まだ着手できていない状況です。
我々は平成32年度からの新試験の、さらにその次の試験での自動採点の導入を考えていますが、数学の数式入力は、その試験でもまだ計画には入っていないだろうと思います。
質問3’(大学教員):数学の先生が記述問題の採点をするときに、答案をぱっと見て、正しい答案かどうかすぐにわかるということは、機械でも何らかの学習ができるはずだと思いますが。
石岡先生:ぜひその辺りは、先生方に研究を進めていただければと思います(笑)。