












高校教科情報シンポジウム2017秋 ―ジョーシン2017秋―
CBTシステムの現状とこれから ~2017年度模試の実施と分析を通して
大阪学院大学 西田知博先生
CBTシステム開発のミッション

今回の「情報学的アプローチによる『情報科』大学入学者選抜における評価手法の開発研究」で、CBT(Computer Based Testing)システム開発のミッションは、思考力・判断力・表現力を測定するための機能性を検討すること、そして、「情報科」試行用のプロトタイプシステムの仕様を策定し構築するとともに、大規模CBT構築への要求要件を整理することです。

今年は、大学入学試験を受験する高校生に近く、現行の学習指導要領の「情報」を学修した大学1年生に試行試験を受験してもらうことを目標として、最初のシステムを開発しました。
それに先駆けて、いろいろな既存のCBTの調査をしました。大規模に使われているのは、医学系で臨床実習前に受ける共用試験です。これはまる1日かけて行っています。このあたりを見ると、かなりの問題数を用意して試験を行っているということがわかります。

また、こういった試験のシステムを提供している会社の方々にもお話をうかがいました。オデッセイコミュニケーションズさんは、MOS(マイクロソフトオフィス スペシャリスト)や統計検定などを行っている会社です。こういった試験のシステムでは、いろいろな作り込みをしているので、話をうかがいながら、我々のシステムはどうあるべきかということを検討しました。

CBTのシステムを作るにあたっては、今回我々が作るのはファーストステップですので、そこでは何をすればよいかということを考えました。そして、CBTとしてはこれが最初ですが、これまでの蓄積として、情報処理学会の情報入試研究会で情報入試の全国模試(注:以下、情報全国模試と表記)を4年間行っていたので、そこで作った試験がCBTで行えるようにすることをミニマムの要求としました。そして、規模としては今年はまず、同時に1大学の1学年程度の規模に対して試験ができるかということを検証することにしました。そして、思考力・判断力・表現力を測る問題について、それぞれの観点でどの程度の正答率があるのか、ということも見ることにしました。
また、CBTというと「タブレットでやってほしい」という意見も出てきますが、これについては普通のパソコンで、キーボードとマウスによる入力というオーソドックスな形にしました。ただし、紙ベースではできない解答のナビゲーションなどCBTならではのインターフェースも加えました。
CBT V1の仕様

今年のシステムCBT V1の仕様を説明します。問題はXMLで記述することとしました。しかし作題者が記述するには負荷が高いので、今後は、例えばMarkdownのような、もっと簡単な形式からの変換やエディターを使った作問についても検討する必要があると思います。
試験問題は情報全国模試での作問方式にあわせ、大きな問題(大問)の定義の中に中問を定義し、その中に個々の設問である小問を入れるという構造で作れるようにしました。
また、紙ベースでは解答欄に解答させていたような問題を、問題文の中に解答箇所を埋め込めて直接答えることができるようにしています。図表については今回は全てイメージファイルで扱いました。

解答方法に関しては、選択問題はオーソドックスにラジオボタンのチェックボックスを使いました。チェックできる個数は、システム上で制限が可能です。
穴埋めは、自由記述か選択肢から選ぶ形ですが、同じ解答欄番号を付与することにより、一つの解答が同じ番号を持つ複数の解答欄に反映される機能をつけました。
また、情報全国模試ではプログラミングの問題などで、短冊の並べ替えで答えさせる形式をとってきていたので、今回もこれはぜひ欲しい機能として採用しました。もちろん、並べた短冊の削除や挿入もできるようにしています。
単語や短文を書く記述式の問題については、今回はあまり長い解答になるものは想定しませんでしたが、残りの文字数がわかるような機能をつけました。
見直しチェックや入力文字数確認機能も搭載
実際の画面を見ていただきます。ログインをすると、インターフェースの説明画面が出てきて、それから問題に進みます。先ほどお話ししたように、選択問題で複数のところに同じ解答が入る場合は、このように同じ解答が問題文の中に表示されるようになっています。
また、画面の左側にはあとから見直すためのチェックを入れておくところもあります。記述式の問題では、入力した文字数がこのように出てきます。


採点については、単純な記号を選ぶような問題は、順不同や組み合わせへの対応も含めて自動採点でできます。単純な記述問題もパターンマッチで採点できますが、これは今回の模試では出題がありませんでした。そのほか、短文で答えるものや短冊の並べ替えに関しては、問題の担当を決めて、採点基準を決めて採点をするという、原始的な方法を採りました。
先ほどのご発表で、人工知能による自動採点では短文の記述問題は難しいという話がありましたが、我々もおそらくそのレベルまで行くのは難しいと考えます。ですので、方向としては、手で採点するものをコンピュータがどこまで補助できるかを、考えていくことになると思います。
東大・阪大1年生のボランティア176人による模擬試験

今回の模擬試験は、阪大と東大の1年生のボランティア176人を対象に、7月の下旬から8月の上旬にかけて行いました。文系が76人、理系が99人、不明(無回答)1人という内訳です。
サーバー負荷について言えば、ロードアベレージでは全く問題ないということです。もちろん、今回は大学の演習室に入る人数程度で実施できるシステムとしてありますので、大規模になると変わってくると思います。
問題の内容に入ります。実は、今回実施した問題のサブセットで、2018年2月に高校生を対象に模擬試験を行いたいと考えています。そのため、具体的な問題をお見せすることはできません。然るべき時にきちんと公開しますので、今回はこの点をご了承ください。

第1問は小問集です。問1はネットワークに関する用語とそれに対する説明のセットを作るものです(関連的思考力:Tc)。用語も説明も同列に並べてあって、「〇と△」「■と★」のように二つずつ組を作って解答欄に入れるもので、紙ベースの問題よりもやや頭を使います。ただ、選んでいくと残りが少なくなっていくのが、視覚的に区別がつきやすくなっています。
問2は、一般的ではない計算規則を読み取って計算する問題(読解的思考力:Tr)、問3は2進の計算で虫食い部分を考える問題です(推論的思考力:Ti)。この二つは数値を答える形です。問4は、グラフの上の石の置き方がどのようなパターンで何通りあるのかを考える問題(Tr、Ti)です。これはけっこう難しかったようです。

第2問はアルゴリズムの問題です(表現力:Ex、Ti)。問1は条件を読んで、選択していくものです。問2では、二分探索のアルゴリズムを短冊の並べ替えで表現します。問題を読み取って、プログラムではなく手順を組み立てる、アルゴリズムの問題です。
第3問は、情報社会系の長文問題です(判断力:Ju、Tr)。プライバシー侵害にあたる行為を選んだり、問題行為とその理由の組み合わせを個数を指定せず全て選んだりします。また、トラブルに関してどのようなところが問題かを20文字で記述するものもあります。さらに、問題行為とその理由を20字で書く問題もあります。
第4問はプログラミングの問題です(Ex、Tr)。問1では、与えられた数の集合の中から条件を満たす整数を選びます。問2と問3で問題を解くプログラムを、短冊の並べ替え方式で、2段階のステップで作っていきます。問2では最初の3つ短冊が入っていて、その後を組み立てていく形で、問3はそれを受けて発展させる形の出題です。以上が今回の模擬試験の内容です。
成績は理系が文系を大きく上回る。プログラミングで大きな差

こちらが今回の模擬試験の結果です。文系と理系とで、差が15点近くあります。特に第4問、プログラミングで大きな差がついています。第3問の情報社会の問題点に関する問題は、文系の方がほんの少し得点が高い。文系の人は、やはりこのあたりが強いかな、という感じですね。ただ、他の問題に比べて差はごく小さいです。第1問の小問集は、ネットワークの問題など、知っているかどうかで差が出たものがあるように思います。

得点のばらつきを箱ひげ図にしてみました。ご覧のように、プログラミングはばらつきが大きいですね。これはある意味、選別の一つのポイントになるものかと思います。
一方、第2問のアルゴリズムの問題は、第1四分位点と中央値がくっつく、つまり同じ値になってしまっています。前半のあてはまる数を選ぶ問題は正解で、後半のアルゴリズムを考える問題は不正解、という人が全体の4割もいる、ということになってしまいました。その意味で、出題側からすると、改善の余地がある問題であったと思います。
各大問題間で相関があるかをプロットしたものが下図です。第1~4問と総得点を縦軸と横軸に置いて問題同士の相関を見ました。これを見ると、第3問の情報社会に関する長文問題は、他の問題と相関がすごく薄いです。もともと文系、理系で差がなくて、文系の方がわずかに得点が高かったところですが、たぶん問題を解くにあたって、手が付けやすいこの問題から取り組んでいったということはあったと思います。
総得点との相関で言えば、やはり第4問のプログラミングが0.86と最も高いですが、第1問、小問集の0.75というのも目立ちます。こういったところが総得点には影響を及ぼしていることがうかがえるという結果になりました。


得点のヒストグラムがこちらです。二つの山があることからもわかりましが、検定すると正規分布ではありません。知識問題や単純な計算がもっと入っていたら、このくらいの人数でも正規分布に近くなったかもしれませんが、やはりプログラミングやアルゴリズムなどの問題は、点数がかなり分かれるので、きれいな分布にはならなかったのではないかと思います。
こちらが文系・理系別に分けたグラフです。山のピークは違いますが、どちらも正規分布にはなりません。

CBTの操作性は問題なし、特に記述問題は好評

今回の受験者には、試験の後に同じシステムを使って、操作感や、CBTと紙ベースとどちらがよいか、などの感想についてアンケートを行いました。
操作性は「非常に操作しやすかった」「操作しやすかった」の合計が90%を超えたので、問題はほぼなかったという結果でした。
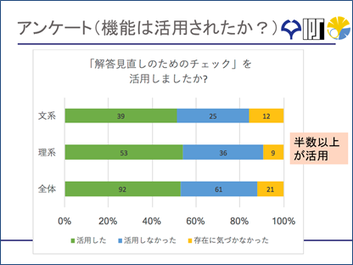
また、回答見直しのチェック機能は、半分使ってくれているので、用意してよかったなという結果になりました。

紙ベースとCBTのどちらがよいか、という質問に対しては、差はそれほどありませんが、なぜか文系はCBTの方が、理系は紙ベースの方がよいという回答が若干多いという結果になりました。

理由を聞くと、たぶん理系の方は、メモは紙で入力はコンピュータというのが面倒だというのが、不満だったのだろうなというのがわかります。また、紙だと問題に線が引けるという意見もありました。目が疲れると言われるのは仕方ありませんね。

これに対して、CBTに対するポジティブな意見というところでは、記入した文字数がリアルタイムで出てくることが好評でした。字が下手なのでありがたいというものもありましたね。
また、選択肢問題や計算問題は紙、プログラミングはCBTに分けてほしいとか、やはりプログラムを動かせるようにしてほしいとか、どうせならタブレットでやりたい、という意見もありました。

全体に対する評価としては、システムとしては問題はありませんでした。ですが、今回の試験がCBTでよかったかは評価が分かれています。ですから、全体としてもっとCBTであることが前提となるような作問が必要だと思います。
CBT V2ではCBTならではの問題を検討

それでは、CBT V2に向けてCBTならではの問題とはどういったものなのか。一つは、アルゴリズムの手順や、プログラムを実際に動かして検証できる問題です。最終的なプログラムや手順を動作させて確認するだけでなく、解答の途中経過も見ることで、思考力・判断力・表現力の評価が可能になると思います。
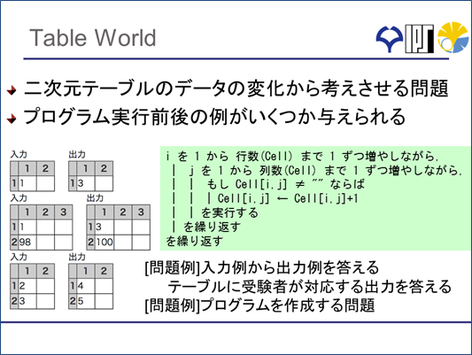
また、テーブルワールドといって、2次元の表のデータの変化から何かを推測するとか、プログラムを考えるといった思考力を問う問題を作ることもできます。

さらに、状態遷移図を書いたり読み取ったり、ということもCBTなら容易に可能です。また、大きなデータを扱って、データベースでいろいろな処理をする問題もできます。クエリを書いて、WEBインターフェースを作るようなものもできますね。
また、RPGのゲームブックのように、シチュエーションを作って、ストーリーが進む中で問題を解きながら、思考過程を見ていくということもできるでしょう。こういったことを考えながら、CBT-V2の開発と作問を進めています。

現在行われているCBTでは、IRTを使って小問で評価するものが多いですが、思考力・判断力・表現力を測るのに小問での評価が使えるかどうかはまだわかりません。来年度に向けては、先ほどお話ししたようなCBTならではの問題と小問を組み合わせて、関連がある結果になるかという検証をやってみたいと思っています。

その他の課題としては、自由記述の採点の問題があります。こちらはまだ自動化されていませんので、採点補助になるような機能をつけることが必要です。また、プログラムに関しては、正答パターンの作成補助やテストケースを利用するといったことが必要かと思います。
また、小問をたくさん作るためには、パラメーターを変えて問題を自動生成できるようなものを作りたいといと思います。今後はタブレットへの対応も課題になると思います
先ほどもお話ししたように、来年の2月頃をめどに、今回行った模擬試験のサブセットを高校で行っていただこうと計画しています。アンケートも含めて授業時間で収まるようなサイズにするようにするなど、現在調整をしています。こちらにつきましては、詳細が決まりましたら、お知らせします。