












高校教科「情報」シンポジウム2018秋(ジョーシン2018)
データ科学の研究者・教育者視点での新情報科の「データサイエンス」
早稲田大学創造理工学部経営システム工学科 蓮池隆先生

もともと、私の専門はオペレーションズ・リサーチで、確率、不確実性下での意思決定、サプライ・チェーン・マネジメント、最適化理論、数理モデルの研究などをしておりました。早稲田大学の経営システム工学科に来てからは、購買行動データの分析、宿泊施設の稼働率最大化を目指した動的価格設定、観光科学、人の移動履歴データから見た行動解析を中心に、意思決定やデータ解析系の研究・教育を行っています。
本日は、そういった研究者・教育者としての視点から、情報科におけるデータサイエンスについてお話していきたいと思います。
データを扱える人材育成の必要性
今の時代、「データを持っていない企業は、競争に勝てない」と言われています。多くのデータを持ち、これをうまく利用することで他社を凌駕できる、という社会になってきているのです。
実は、多くの会社には、意外なほどデータの蓄積があるものです。問題は、その膨大なデータを、どのように活用したらよいのかわからないということです。
データを的確に分析して活用できれば、少ないデータでも勝ち目がないわけではありません。データを扱える人材をきちんと育てていけば、その会社は大きく成長していくことができるはずなのです。
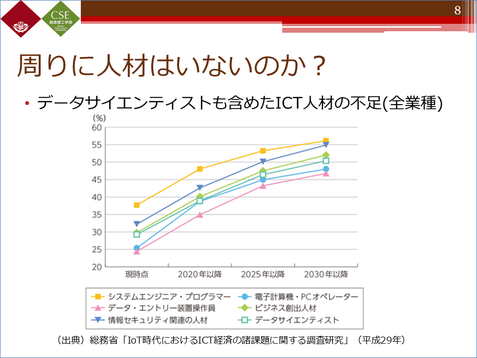
こちらは、平成29年の調査ですが、ICT人材は、全般的に不足していくと分析されています。
もちろん、データサイエンティストをたくさん抱えている企業もあるのですが、一般的には、他のいろいろな業務をしながら、その合間にデータ分析をしているというのが現状です。
データサイエンティストというのは、課題解決とかデータ内容の分析といったイメージで捉えられがちなのですが、私の個人的な見解としては、例えばプログラミングやエンジニア系の仕事ができて、統計解析・機械学習・データマイニングなどのデータ処理ができる、かつ分析ができた上で、解決方法が提示できるという人材だと思っています。こういう人材を、日本は育てていかなければなりません。

この「処理」「分析」「解決方法の提示」という、三つの要素すべてを網羅できなくても、最低、このうちの二つはできる人材を育成する必要があります。プログラミングができて、その分析がきちんとできる人。もしくは、プログラミングはできないけれども、統計の結果分析ができて、それを伝えることができる人、といった要領です。
一人が二つできれば、チームにすることで仕事を進めていけます。大学教育の中で、そんなデータサイエンティストを育ててほしいというのが、社会からの要望ではないかと感じています。
そう考えると、早稲田大学経営システム工学科は、データサイエンティストを育てるのに、ぴったりな学科のように思えてきます。
早稲田の経営システム工学科は、もともとIE (インダストリアル・エンジニアリング)の学科ですが、統計学や先端のデータマイニング手法、人工知能といった研究フィールドの重要性が評価されて、現在は経営システム工学科の中でも、こういった分野がメインフィールドとなりつつあります。

全学年で経営工学を学んでビジネス系の知識を定着させ、データサイエンス系の教育プログラムでは、1年生でプログラミングと基礎統計学、2年生でそれを少し応用した統計学・OR(オペレーションズ・リサーチ)・機械学習、およびデータマイニングの基礎、3年生でその応用の深い部分を学習し、どの研究室に入るかを探る、という流れになっています。

いろいろなデータの扱い方を基礎から応用まで学ぶことが、さまざまな経営部門に就職する際、非常に役立ちます。
この経営システム工学科の経験を踏まえ、教科情報について、考えていきたいと思います。
データの処理・分析と、高校の「教科情報」
●学習指導要領の「理想」とコンピュータの「進歩」とのズレ

新しい高校の学習指導要領を見てみると、「情報の科学的な理解」に裏打ちされた情報活用能力を育む」と記されています。目的に沿って、的確な方法で情報を収集し、さらにそれを分析して実地で生かすことのできる人材を育てるということだと思います。では、これが、具体的にどういうことか、ということをお話していきます。
学習指導要領の解説では、さらに「データに基づく現象のモデル化やデータの処理を行い、解釈・表現する方法について理解し、技能を身に付けること」と、書かれています。「データ解析をできるようになりましょう」ということですが、この辺りは、実際コンピュータを使えば、誰でもできることなのです。と言うのも、ハード面では大規模データが扱えるような計算機が登場しているからです。また、ソフト面ではSPSSやSAS、無償のR、Excelなど、データ解析ソフトがたくさん出ています。

極論ですが、データさえあれば、何も考えずにボタンをクリックしたら、結果が出てしまうわけです。もちろん、コンピュータの中では、重回帰分析、因子分析、いろいろな手法が使われています。
ただ、手法の中身に強くなくても、数字としてはじき出されてくるとそれだけで形になりますので、いろいろな分析結果を利用することは、可能になっている、というのが現状です。
●ソフトを動かすためのプログラミングができても、中身を理解していないと誤った結果を招く
私は、現在大学1年生のC言語を教えています。その初回レポートの感想を書いてもらったのですが、何人かの学生から、「なんでPythonをやらないんですか?」「今やデータ解析に用いるディープラーニングや機械学習のプログラムは、Pythonで書くのが主流なのに……」という意見が出てきました。
実際、少し勉強すれば、高校生でもディープラーニングや機械学習のアルゴリズムやプログラムを実装することは可能ですPythonという非常にわかりやすい言語が出てきて、例えば、「データ解析ならこういったプログラムを1行2行書けば、重回帰分析ができますよ」というパッケージが用意されているので、それ呼び出せばいいわけです。中身を理解していなくても、呼び出すことぐらいは普通のプログラミングでできてしまいます。しかし、中身を理解していないと、正しい結果が出ないことがあり得るのです。
例えば、ある店舗のオーナーが、月間の売り上げを考えて、重回帰分析を用いたとします。来店客数と平均気温と雨の日数、降水量とイベントの有無が関わっていると考え、重回帰分析をかけて、結果を出しました。これで、それぞれの要因が、売り上げ数にどのように関わっているかがわかります。
ところが、この結果を次の月に適用してみたところ、まったく売り上げが伸びない、ということになってしまいました。これは、重回帰分析の中身を知らないために、起こった悲劇です。きちんと勉強をしていれば、明らかに相関関係が強い要因(この例では「雨の日数」と「降水量」)、つまり「多重共線性」が悪さをしているということがわかりますが、思いつく項目を機械的に入れただけでデータ解析をしてしまったため、誤った結果を招いてしまったのです。

他にも、「擬似相関」や「ディープラーニング」などにも、陥りがちな「罠」があります。中身を理解していないことが原因で、おかしな分析結果を招いてしまうという例です。

「間違った分析」や「理由がわからないまま」というのはよくないと、高校生に伝えることも大切ですが、なぜそのような結果が出てしまったのかという分析力を、しっかり身につけさせることが、高校での教科情報の役割ではないかと思います。あり得ないことを、「明らかにおかしい」と感じるところから疑問を広げ、解決方法を導き出すのが、理想的な流れなのではないでしょうか。
●分析のポイントは「データの質」
「ビッグデータ」という言葉が広まり始めた頃、同時に「何でもいいからデータを片っ端から集めて分析すれば、何かいい結果得られるでしょ」という、安直な発想が広がってしまったような気がします。そのせいで、種々雑多なデータが持ち込まれるようになってしまった面があります。
実際に私が体験したのは、車の移動履歴データを解析して、行動の効率化をしたいという依頼でした。依頼の目的自体は「長距離移動時には休憩場所を適切にスケジュールしたい」、「渋滞なども考慮して運行ルートを決めたい」という、非常に真っ当なものだったのですが、車の詳細な種別もわからないものでした。例えば、車がトラックだと仮定したとしても、小型トラックならコンビニに停めて休憩をとることもできますが、大型トレーラーなどであればコンビニには停められません。
また、スマートフォンと同じように、車からデータを取る際にも1台1台固有のIDが振られていることが普通なのですが、なぜか複数台に同じIDが割り振られ、奇妙な行動をとるデータも多く見られました。
要するに、データの質がこのようなものでは、今話題の最先端AIで分析したとしても、目的に合った結果は得られないということです。やはり人間が、データの誤りに気付くしかないのです。
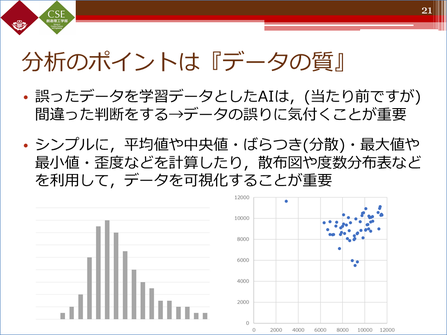
実際に簡単な計算でも、その誤りに気付くことができます。平均値や中央値、最大値や最小値、最頻値などを見て、「ああこれは誤りだ」というのがある程度わかることが必要です。例えば、身長の分布を見たとき、単位がcmだとして、最大値が5000とか最小値がマイナス200などというのは、明らかにおかしい数値です。
そのためには、散布図や度数分布表などを使って、データを可視化する必要があります。データの質を高める上で、ぜひ取り入れてほしいものです。
実は、学習指導要領の解説にも、「目的に応じた適切なデータを集めましょう」ということが書かれています。その意味でも、データサイエンスにおける情報活用能力の育成というのは、目的に合った質の高いデータを持ってくる力と、データをどういう手法で分析するかということ、そして、分析結果を正しく理解し伝える能力を養うことと言えるでしょう。

こういうことを、高校生のときからやっておくと、大学に入ってからの研究、そして、社会に出てからの応用・実践にも、かなり活きてくると思います。
また、これは理系文系を問わない能力です。平均値や最大値・最小値を見て、データが合っているのかどうかを判断するのは、いわゆる高度な数学ができる・できないというのとは関係ない話だからです。
●Society5.0の世界で活きる高校の「教科情報」
さて、最後はSociety5.0と高校の教科情報の関わりについてです。
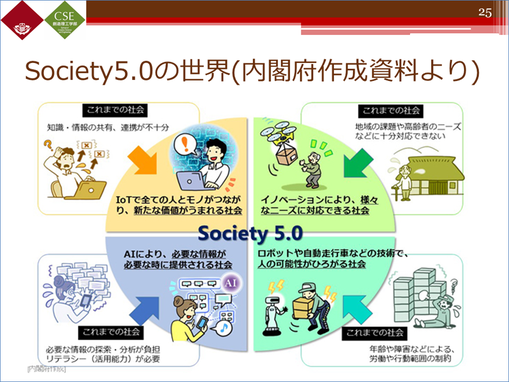
Society5.0については、皆さんご存知かと思うので、具体的な説明は省きますが、AIやロボットがあったり、買い物に行けないご高齢の方にドローンで荷物を飛ばしたりといった、サイバー空間(仮想)とフィジカル空間(現実)を融合させた社会ということになります。
4.0のときは、人がクラウドにアクセスしなければなりませんでしたが、5.0では自動でいろいろなことができるようになります。今の高校生が社会人になったときには、まさにSociety5.0が実現されている世界でしょう。その辺りを踏まえた教育を行ってほしいと思います。
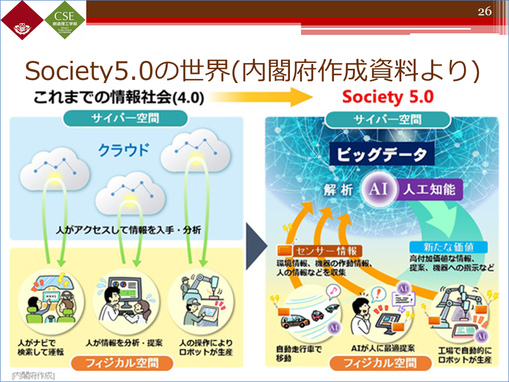
IoTの実現が進んでいくと、今よりもさらに膨大な情報が集まります。その中からどれとどれを使うのか、どことどこをひも付けするのかなど、最終的に目的に沿ったデータを組み合わせていく力が必要となります。
また、情報と情報の連結を見ながら説明する力も、より大切になってくるでしょう。高校の教科情報の授業では、近い将来の環境を見据えながら、授業展開していただければと、思っています。
データサイエンスで必須なのは、良質なデータと「ホワイトボックス」での解析能力
ここ数年私が感じているのは、情報教育やデータサイエンスの役割としては、「目的に合った情報を質が高い状態で収集する」ということです。結局、これができないと、いくらデータ解析をしても、おかしな結果しか出てこないからです。
それから、データサイエンスは実社会とダイレクトにつながるため、「なぜそのような結果になったのか? 」ということを、責任をもって説明する必要があるということです。ソフトウェアまかせのブラックボックスで解析して「結果が出ました」ではなく、情報やデータの出どころ・信頼性や信憑性・データ解析手法の詳細をできる限り知った「ホワイトボックス」の状態での解析能力が必要なのです。
データサイエンスを教えるには、中身を知ることも重要ですが、もう一つは「データを扱う、データを触る」ということが必要です。実際のデータに触れないと、「何かがおかしい」と感じることは難しく、この辺りを意識した教育をしなければなりません。また、教員の質という問題もあります。やはり、大学を卒業して教員になるわけですから、大学教育の中で、情報教員をしっかり育てることも重要な役割だと考えています。
【質疑応答】
Q1大学教員 : データサイエンスの勉強で、データを扱わなければならないということになると、どういう言語を使えばよいのでしょうか。
蓮池先生 : Python系のわかりやすい言語からスタートすると、「こういうアルゴリズムで作られている」という部分を、どう教えるのかが課題になりますし、Cなどのいわゆるベーシックなプログラミング言語では、ハードルが高くなってしまいます。
個人的には情報数理寄りの立場にいますので、まず中身を知ってからということで「CをやってからPython」と思っているのですが、教育という面でどうすればいいのか、正直難しい面があり、今後の課題になっている、ということでご容赦ください。
Q2大学教員 : 高校には、数学と情報という科目がありますが、高校の数学には統計が入っています。この状況で、情報と数学の住み分け、あるいは協力の仕方、この辺りについてどうお考えでしょうか。
蓮池先生 : まずは数学の方で、統計の理論を学習することが重要だと思います。そうすると、実際にデータを使わないとわからないことが出てきますので、情報の方でそれを実証していくというのがよいのではないかと思います。数学の理論だけでは出てこないような実現象を、情報で学ぶというイメージです。その意味で、数学と情報の連携は必要で、それをやってこそ、教育として意味のあるものになると考えています。
Q3高校教員 : 高校の授業でデータサイエンスをやろうとしたとき、データを用意しなければならないのですが、効率のよいデータの集め方がありましたら教えてください。
蓮池先生 : 公共のオープンデータが、使いやすいのではないでしょうか。例えば、「ごみ処理施設のごみの収拾量と焼却の熱量の関係」などというデータは、市区町村のサイトなどで公開されています。外れ値や欠損値もあり、最大値・最小値・平均値などを出すことができて、実社会に近い分析を学んでいくことができると思います。
高校教科「情報」シンポジウム2018秋 講演より