












大学入試を中心とした情報分野の学力評価手法の検討シンポジウム2024
典型的な問による評価手法の開発
日本大学 谷 聖一先生
PBT・CBT双方の作問手法とその手順書を作成するために

我々グループ1の大きな目標は、情報の知識体系に基づいて、きちんと評価できるような大問や中問を作成するための手法、およびその手順書を作成することです。
問う能力や評価基準を学習指導要領と関連付け、さらに先ほど植原先生からご紹介のあった「阪大プロジェクト」で作成した「思考力・判断力・表現力を評価する問題作成手順」(※1)をバージョンアップしていきます。
この評価の実施方法については、PBTとCBTの両方を対象とします。我々は、PBTでもある程度評価ができるとは考えていますが、やはりPBTでは限界があるのではないかということは、直感として持っています。
ですから、「PBTではこのような能力を測ることができ、CBTではPBTでは測れない、こういった能力を測ることができる」ということを明らかにすることが、目的の一つになっています。

その第一歩として、今年6月・7月に、高校生に参加いただいて模試を行いました。今回の模試は、将来的に作問の手順書を作成するという、先ほどのゴールに近づくためのヒントとして、基礎的なデータを集めることが一つの目的で、あくまで予備的な調査という位置づけです。

今回の模試は、多くの人に参加していただくためにCBTで実施しました。今回、我々のグループの「一般的な問題」は、いったん共通テストと同様に、多肢選択問題をマークシートで答える形式で作成し、これをCBTに載せました。一部、CBTに寄せた解答形式になっているものもあります。
例えば共通テストで『37』という数値を答えるときには、『3』と『7』をマークしますが、今回は『37』と直接入力してもらう、といったことです。問題の内容としては、基本的には共通テストの出題と同様なスタイルで、CBTでもPBTでも出題できる問題です。
ただ、高校の授業時間内で実施するためには、問題の制約があります。共通テストは60分で大問4問、1問あたり15分ということになります。なお、試作題は第2問がAとBの2つの問題に分かれています。来年1月の本試が試作問題と同じ形式であるとすると、かなりボリュームがあることになります。
我々の模試は、高校の授業内で行えるように、40分で行うことにしました。
まずIRTの問題を、20分で20問解いてもらい、その後の20分で、10分間で解くような「中問」サイズの問題を2問解いてもらいます。中問というのは、大問が1問あたり15分なので、10分であれば中問、という便宜的な名づけです。その分、時間は少し短く、ボリュームも少なくなっています。問題のスタイルは、多肢選択問題です。
「一般的な問題」は、「コンピューターとプログラミング」の中でも、アルゴリズムとプログラミングに関する部分の問題(以下、「問題P」)が2セット、モデル化とシミュレーションとデータ活用に関する問題(以下、「問題M」)が2セットで、これらとIRTの問題2セットを組み合わせると、全部で2×2×2の8パターンになります。
IRTの問題は、今後何回も使っていくため公開していませんが、「一般的な問題」の方は、下記のサイト(※2)で問題文、正解と配点、出題意図を公開しています。
こちらの問題は、共通テストと同様の形式になっています。先ほど植原先生のスライドで紹介されたCBTのスクリーンショットとはスタイルが違いますが、問題の内容は同じです。
※2 https://emiu.sfc.keio.ac.jp/wp/?p=169

※クリックすると拡大します
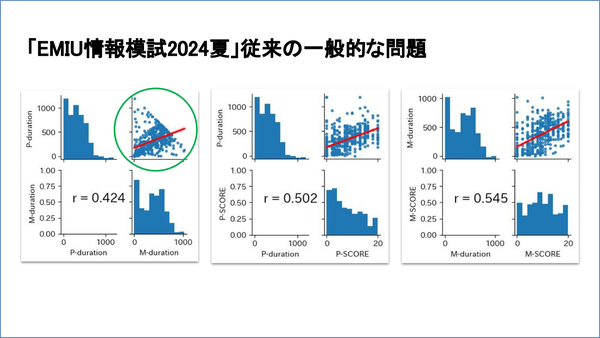
「一般的な問題」の解答状況
今回の模試の解答状況についてご説明します。
参加者が520名で、先ほどの問題Pのセット1か2と、問題Mのセット1か2のどちらかが割り振られます。各問が20点満点です。
受験した人の中には、受験はしたけれどPやMの問題を解いていない人もいます。そこを整理したのがこちらの表になります。

問題Mのセット1の得点は、平均も中央値も10点くらいで、これなら普通かな、というところですが、その他のセットは得点がやや低くなっています。

※クリックすると拡大します
中問の解答時間は、1問10分(600秒)想定でしたが、平均すると約300秒、5分を少し超えるくらいで解いています。中問の中の個々の小問についての解答時間は取っていません。
問題P(プログラミング)は、ずっと粘って解いている人もいますが、中央値を見ると、セット1の方がかなり短くて、3分そこそこで解いてしまっています。易しい問題ではありますが、問題数もあるので、3分で解けるのかなとは思うのですが、3分で満点を取っている人もいます。

※クリックすると拡大します
時間をかけなくても解ける人、時間をかけても解けない人も
解答時間は、問題Pと問題Mで合わせて制限時間20分です。システム設計上、それぞれの問題で10分ずつ、ということにはしませんでした。
一番左の緑の○で囲んだグラフは、縦軸が問題Pにかけた時間(秒)、横軸が問題Mかけた時間です。解答時間は合わせて20分、1200秒です。
このグラフ上に右肩下がりのラインが表れていますが、ここは縦軸と横軸の時間数の和が1200(秒)になるところで、ここに張り付いてる人は、2問合わせて20分を使い切った人となります。このラインの下にいる人は、20分より短い時間で解いた人ということです。
これを見ると、問題Pだけで20分使い切って、問題Mにはほとんど時間を使っていない人も、その逆のパターンの人もいます。
ただ、本当に20分間問題Pに取り組んだのか、解き始めて面倒になって、そのまま放置してしまったのかはわかりません。この人たちがどのように解答してるのか、もう少し詳しく見る必要があるかと思います。
※クリックすると拡大します
時間をかけたらちゃんと解けているのか、というところを見たのがこちらです。横軸が得点、縦軸が解答時間です。先ほど植原先生のお話にあったように、ほぼ山形の分布になっています。
これを見ると、時間をかけても解けていない人もいれば、数十秒で解いてしまっている人もいます。これは、問題PもMも同じような傾向です。
これは全体的な傾向であって、ここから何か結論が言えるというわけではありませんが、このような形になっている、ということを御紹介しておきます。
※クリックすると拡大します
実際の解答を見てみると…
実際の問題を見てみましょう。問題自体の質だけでなく、CBTで行っているので、システムに慣れていないので答えづらかった、という問題がなかったかを確認することも必要です。さらに、プログラムの問題が難しすぎたかもしれない、という可能性もあるかと思います。問題の詳しい内容は、先ほどのEMIUのサイトをご覧ください。
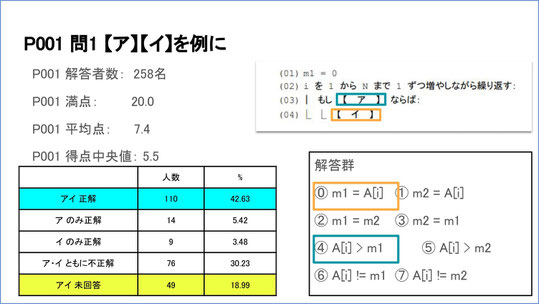
問題Pのセット001の問1は、変数iを1からNまで1つずつ増やしながら繰り返し、条件があれば、代入しますよ、という問題です。
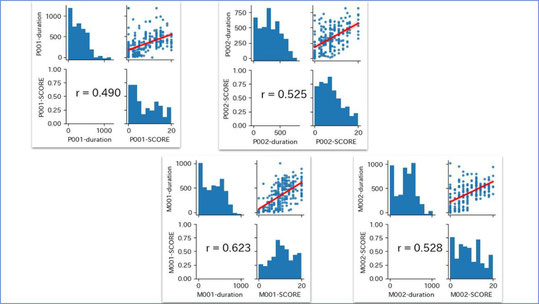
この問題については、我々は誰でも解ける、とある程度期待していました。この問題を解答した人は258人で、正解した人が110人。満点は20点、平均7.4点、中央値が5.5点でした。
ここでは、どちらかだけでも答えられている人の割合も出していますが、本来は、アとイの両方が正しく答えられたら正解です。これが110人、42,6%。両方不正解の人が76名、約30%いました。

※クリックすると拡大します
アとイに何が入るのか、ということを考えるなら、アの方は「もし何々ならば」なので、条件文が来るはずですね。実は、この選択肢の上の4つは代入文、下の4つは条件文なので、事実上それぞれ4択になっています。それでも、アに代入文を入れたり、イに条件文を入れたりしている人も相当数いました。一方で、そもそも最初からこの問題に解答してない人が2割近くいました。
※クリックすると拡大します
こちらは問題Mのセット001で、8~9割できていた問題です。かなり長い問題文から条件を読み取れているかを見る問題です。こういった問題はよくできていました。

※クリックすると拡大します
一方こちらはデータ活用の問題で、多肢選択ではなく数値を入れる問題です。
自動販売機の状況の変化をシミュレーションします。はじめにリード文で状況の説明があって、問いの中でシミュレーションをして、お釣りの最大金額がどうなるかを答えるものです。
これは正解が「90」なのですが、「90」と「90.0」が2つあるのは、数値を全角で入力した場合は整数に変換する、という仕様になっていたからです。
この問題は、導入で問題設定を理解してもらうために作ったものでしたが、それにしては少し難しすぎたかな、と思っています。今後、問題ごとに分析して、どこに課題があったのかを検討して、次の問題セットを作っていきたいと思っています。

※クリックすると拡大します
よくできていなかった人・できていなかった人それぞれの成績を見てみると…
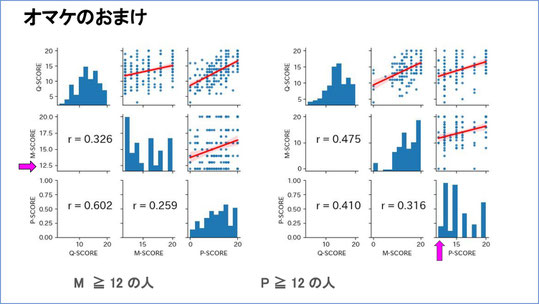
こちらはおまけの分析です。IRTの問題は解いたのに、問題Pは解かなかった人が45人いました。この人たちは、問題Pだけでなく、問題Mも解いていません。
そこで、問題Pが0点だった人が、問題Mや、IRTの問題がどのくらいできているのかを見ると、IRTは真ん中に山ができていますが、問題Mは右肩下がりになっています。

※クリックすると拡大します
逆に、問題Pがよくできていた人(20点満点の12点以上)は、ざっくり上位25%になります。この人たちは、IRTも問題Mもそれなりによくできています。

※クリックすると拡大します
問題P、問題Mがよくできていた人は、IRTとの相関では山ができていますが、問題M、問題Pの方は、山ではなくて、はっきりした山はできていない、という形です。なお、ピンクの矢印が入っているグラフは、得点の軸が12点から始まっていますので、ご注意ください(注:ピンクの矢印がない軸で0から始まっていないものが他にもあります)。
※クリックすると拡大します
できる人たち同士で見ると、問題Pができている人と、問題Mができている人は、属性が少し違うのではないかと感じられます。
これもこれだけで結論できるところではありませが、こういった傾向がある、ということをお示ししておきます。問題ごとにどのような誤答があったか、ということは出していますので、今後はこれらを確認しながら、問題として機能していたのか、機能していなかった問題はどういうことが原因であったのを解明して、次の問題セットにつなげていきたいと思っています。
出題範囲を「情報I」の全領域に広げ、作題マニュアルの完成を目指す
今後の課題として、「プログラミング問題に取り組んでもらえない人が一定数いる」というものがあります。これは、我々の課題だけでなく、情報教育そのものの課題かもしれません。
将来的には、出題範囲を「情報Ⅰ」全体に広げていくことともに、作題マニュアルを作ったり、PBTの限界を検討して、CBTらしい問題についても検討していきたいと思います。
今後は来年に向けて、問題をブラッシュアップして、今回と同じフォーマットで、共通テストでそのまま出題できるような問題で、もう1回模試を実施したいと思っています。

大学入試を中心とした情報分野の学力評価手法の検討シンポジウム2024 講演