












大学入試を中心とした情報分野の学力評価手法の検討シンポジウム2024
グループ2 多肢選択問題によるIRTに基づく評価手法の構築
慶應義塾大学 植原啓介先生

グループ2の「多肢選択問題によるIRTに基づく評価手法の構築」について報告します。
私たちのグループの目的は、IRTでの出題形式となる多肢選択問題等の自動採点可能な問題による評価手法を開発すること、作問のBest Current Practiceとしての手順書を作成すること、そして多肢選択問題でどれくらいの範囲(分野)、レベル(深さ)、思考力・判断力・表現力・応用力まで確認できるかを明らかにすることです。
要は、範囲、レベル、思考力・判断力・表現力・応用力の軸があったとき、この部分はIRT向きで、この部分はIRT不向きだ、ということを明らかにするということです。

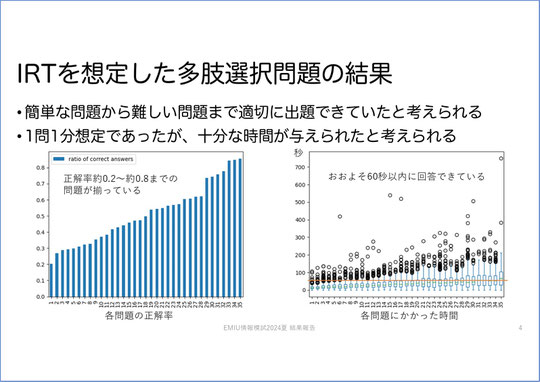
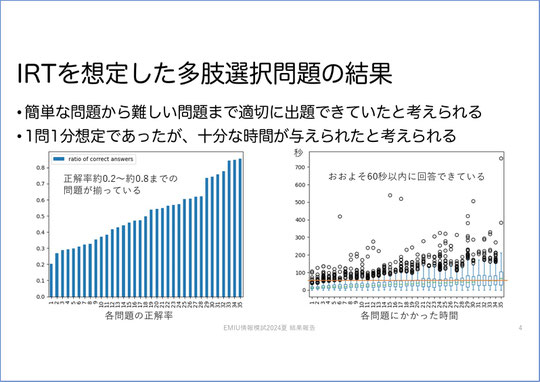
今回の模試をIRTの観点から見ると
左のグラフが、今回の模試で出題したIRTの問題35問の正解率です。35問というのは、IRTの2つのセットに共通する問題5問、どちらか一方だけに出題している問題15問ずつの、合計35問ということです。
この35問は全て4択問題ですが、中には正解率が25%を下回っているもの、つまりランダムに選ぶよりも正解率が低い問題から、正解率が8割超えるものまで、さまざまでした。
今回のIRTの問題は、20分で20問解くことになっているので、1問あたり1分想定です。我々も出題にあたって、1問あたり1分というのは短かすぎないか、ということをかなり議論しました。
実際にやってみたところ、右のグラフのように、大体が60秒以内に回答できていました。グラフの丸い点は外れ値です。箱ひげ図を見ていただくと、箱の中の緑のラインが中央値ですが、これが60秒(黄色のライン)を上回っているのは1問だけです。つまり、ほぼ全問が1分以内で解かれています。もしかしたら、1分で解けなかったら諦めて適当にマークしている可能性もありますが、ほぼ1分で答えられた、という状況でした。
※クリックすると拡大します
IRTの問題例
ここからは、IRTの問題の例についてお話しします。
IRTでは、今後も同じ問題を出題するかもしれないので、これまでは、基本的に公開しないと申し上げてきましたが、ご協力くださった先生方から、具体的な問題がないとさっぱり分からない、とご意見をいただいたこともありまして、今回は本邦初公開で、3問ご紹介します。
1つ目が、問題を解くための作業手順を過不足なく説明したものを何と呼ぶか、最も適切なものを4つの選択肢から選ぶ、というものです。これはさすがに正答率が一番高くて、84.4%でした。もちろん正解は1番です。

この問題は、先ほどご紹介した、多肢選択問題の作問方法の1.で作ったもので、一番簡単だろう、と想定したものでした。結果として、予想通り正答率が一番高くなりました。このような問題が35問の中に数問あり、いずれも正答率が高くなりました。
こういった問題は、たくさんある問題の中にいくつかあってもよいけれど、このような問題だけで構成してしまうと入試にはならない、ということです。

次が、正答率が最も平均に近かった問題で、正答率57.4%でした。「このプログラムを実行したときに得られる出力はどれですか」という問題です。
プログラミングの要素としては、ループと条件分岐、配列が含まれる問題です。先ほど井手先生から、配列が入ると結構難しい、というお話がありましたが、そのお話を聞くまでは、典型的なループの問題なので、まあまあできるかな、というのが我々の感想でした。こういった齟齬はどうするのか、ということについては、検討する必要がありそうです。単純なループによる処理だけを扱って、配列や条件分岐がない問題は、この問題よりさらに正答率が高くなっています。

35問の中で、最も正解率が低かったのがこちらです。「変数a、b、cの値の中で、最も小さな値をdにセットする処理(記述)はどれか」というもので、正解率は20.3%(無回答を含む)で、ランダムに選ぶより低い、というものでした。
正答は選択肢1です。それぞれの選択率を見ると、1が20.7%(無回答を除く)、2が26.8%、3が13.8%、4が38.7%で、これが、一番誤答を引き出しているプログラムになります。
これがなぜ選ばれやすかったのか、我々もいろいろディスカッションしたのですが、原因がまだわかりません。心当たりのある先生がいらっしゃいましたら、ぜひ、お教えいただければと思います。

※クリックすると拡大します
今回、一般的に変数の上書きが行われる問題は、他の問題よりも正答率が低くなる傾向が見られました。変数の上書きは、手で書いてトレースしないと難しいと思います。我々はCBTで実施していますが、一応、メモ用の紙を手元に持って受験してもよいことにしました。ただ、気楽に受験している人は、紙と鉛筆まで準備していなくて、トレースすることが難しかったという原因もあるのかな、と思っています。
もうひとつ、我々が仮説として持っているのは、選択肢1は大なり記号(>)を使っていますが、問題は、「小さい値をセットする」ことになっています。ですから、大なり記号を使っていながら小さい値を見つけるという、この不整合によって頭が混乱して解けなかったのかもしれない、ということです。これらの問題ごとの解答の傾向に関しては、今後我々の研究の中でもう少し詰めていって、こういった問題を出すとこんな結果になる、ということを明らかにして、皆さんにお伝えしていきたいと思っています。
今回の試験で上位25%の人たちが、どのような解答をしたかを見てみました。その結果、さすがに一番難しかった問題の正答率は28%程度でした。
先ほどの全体の正答率と比較すると、上位25%の人はこういった感じのグラフになる、というのが違うところかな、と思います。

※クリックすると拡大します
※クリックすると拡大します
正答率が低かった問題の原因を探ることも必要
IRTを想定しているので、IRTで必要となるパラメータを計算してみるために、項目応答曲線を書いてみました。
おおむね弁別性のある適切な問題になっていますが、赤で囲んだ辺りが、出題するには適切ではない可能性があり、こういうものに関しては、今後、原因を探って、より良い作題マニュアルを作っていければと思っています。

※クリックすると拡大します
今後は、今回得られた知見をもとに、正答率が低かった問題については、なぜそうなったのか、ということについて研究を進めていきたいと思います。この原因については、高校の現場の先生方や、入試や模試に携わっている方々とディスカッションできればと思っています。
また、こういった仮説を持っているので検討してほしい、確認してほしいというリクエストがあれば、我々もぜひ検討してみたいので、ご連絡いただければ幸いです。

大学入試を中心とした情報分野の学力評価手法の検討シンポジウム2024 講演